Redis 用集合存储集合
不要将集合拆分存储,用集合存储集合。
一、优点 - 节省空间
1. key-value 的空间占用
数据结构占用:
如果是 String 类型,则除了记录实际数据外,还需要额外记录数组结束符、数据长度、空间使用等
元数据占用:
在 Redis 中,每个值都有一些元数据(包括最后一次访问的时间、被引用的次数)需要记录。Redis 会使用一个 RedisObject 结构体统一记录这些元数据,同时指向实际值,一个 RedisObject 包含 8 字节的元数据和 8 字节的指针。
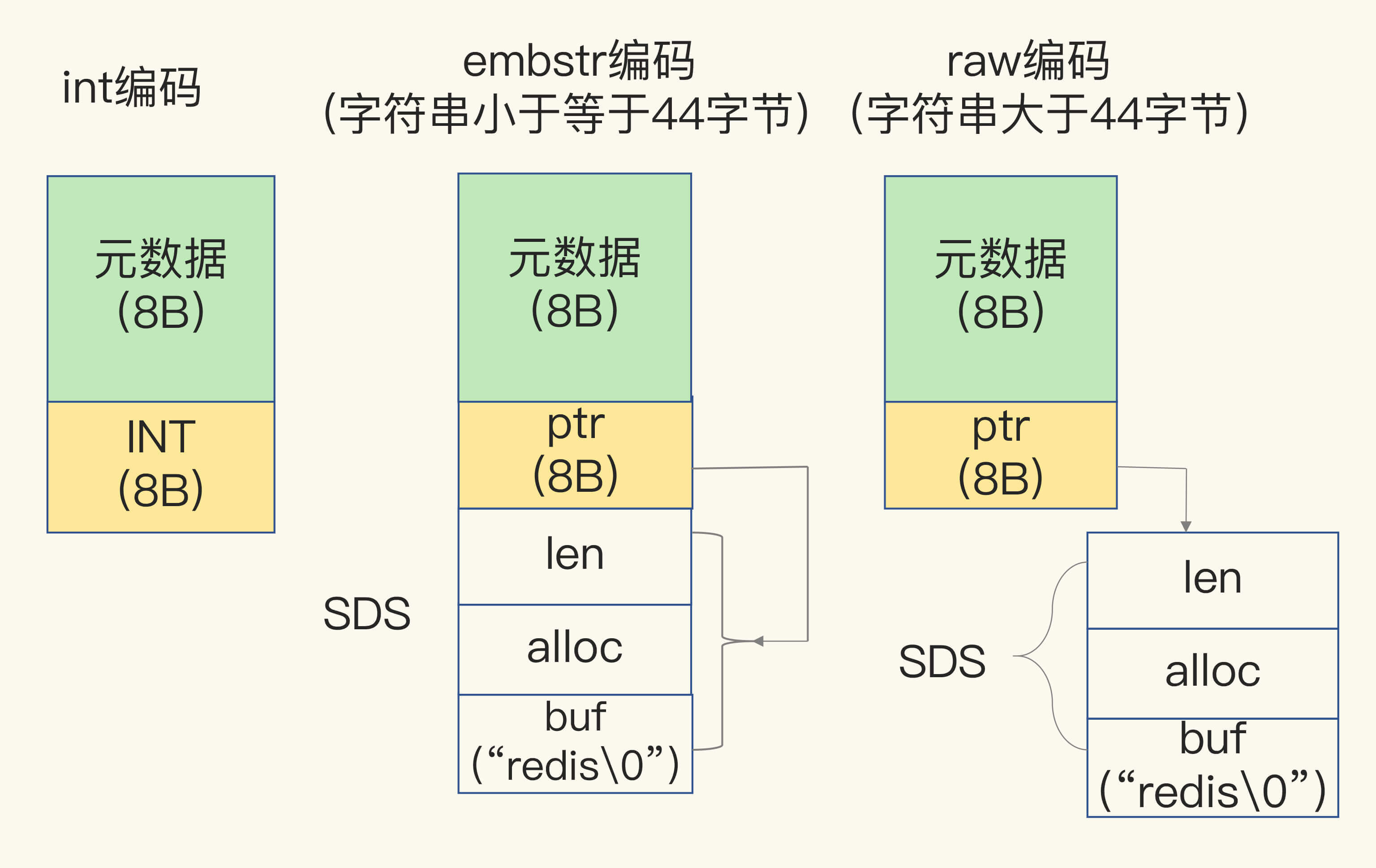
- 如果数据是 Long 类型的整数,则指针会被直接复制为数据,避免了额外内存空间和寻址的开销
- 如果数据是小于等于 44 个字节的字符串,则 Redis 会将 RedisObject、字符串在内存中放置到一起
- 如果数据是大于 44 个字节的字符串,则 Redis 不会将它们放到一起,而是为字符串分配独立的空间
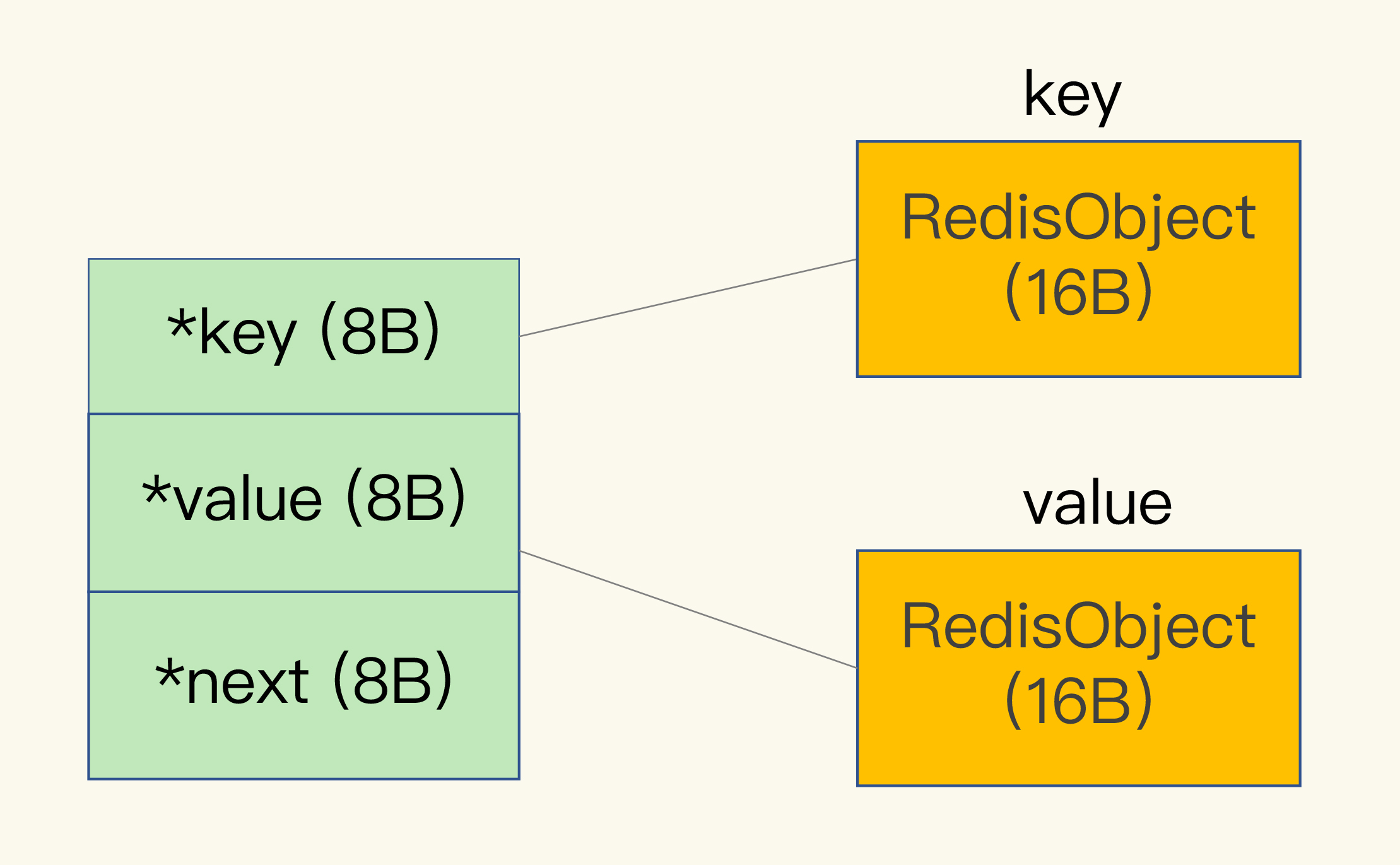
哈希表项占用:
由于键值对最终都要放置到哈希表中,因此 Redis 还需要维护一个额外的哈希表项。每个哈希表项是一个 dictEntry 结构体,由三个 8 个字节的指针组成,分别指向 key、value、哈希桶中的下一项,又由于 Redis 的内存分配按 2 的幂次数分配,因此共占用 32 个字节。
2. 集合的空间占用优势
假设要存储每个用户的粉丝数,
可以这样:
2
3
4
5
6key value
id1 100
id2 200
id3 105
id4 120
···也可以这样:
2
3
4
5
6key value
fans 集合 id1 100
id2 200
id3 105
id4 120
···如果将集合拆分存储,每增加一个集合元素都要额外增加数据结构占用、元数据占用、哈希表项占用。
如果用集合存储集合,一个集合只需要一个元数据和一个哈希表项,且每增加一个集合元素只需要额外增加数据结构占用(并且集合项的数据结构占用经过优化,小于 String)。
二、优点 - 统计
聚合统计:假设有对多个集合的聚合运算(并集、交集、差集计算),可以使用 Set,它自带聚合运算命令
集合运算的计算复杂度较高,执行可能导致 Redis 实例堵塞,可以用以下两种方式解决:
- 选择一个从库,让它专门负责聚合运算
- 将数据读取到 Server 中,在 Server 中完成集合运算
排序统计:假如要存储有序结合,可以使用 List 和 Sorted Set
List 和 Sorted Set 属于有序集合,其中:
- List 按照元素进入顺序进行排序
- Sorted Set 按照元素的权重排序
二值状态统计:假设需要维护一个集合的状态,并且这个状态取值只有两种(0 和 1),可以使用 Bitmap
Bitmap 的底层是二进制的字节数组,用数组的每一位表示一个元素的二值状态
基数统计:如果希望统计集合中不重复元素的个数,可以使用 Set,它能够保证元素不重复。另外,也可以使用 HyperLogLog,它能够在节省空间的情况下 “估算” 基数。
参考
- Redis
- Redis 教程 | 菜鸟教程
- Redis数据库学习教程(快速入门版)
- Redis 核心技术与实战