Redis 消息队列
本文将介绍 Redis 对消息队列的实现。
一、消息队列
1. 工作过程
- 如果 A 要将消息发送给 B,则 A 将消息发送给消息队列,发送后 A 便可以不再关心消息状态,可以继续执行其它操作
- B 从消息队列中读取消息、处理
一般将 A 称为生产者,将 B 称为消费者
2. 必须满足的三大需求
消息有序:消息队列应该能够保证放入其中的消息能够按顺序被消费者读取
防止重复消费:消费者从消息队列中读取消息时,可能因为网络堵塞而出现消息重传的问题,应该避免消费者对同一个信息重复消费
保证消息可靠性:在消息处理过程中,可能因为故障或宕机导致消息无法处理完成,应该提供重新读取消息并再次处理的机制,以保证消息可靠性。简单来说,应该防止消息在处理结束前丢失
二、基于 List 的消息队列
1. 简单的 List 消息队列
生产者用 LPUSH 命令将消息写入 List,消费者通过 RPOP 命令从 List 的另一端依次读取消息。
写入数据时,List 并不会主动通知消费者,因此如果消费者想要及时处理消息,则需要不停地调用 RPOP 命令。因此,即使没有新消息,消费者也要不停地尝试获取消息,这将会带来不必要的性能损失。
2. 堵塞式读取的 List 消息队列
Redis 提供了 BRPOP 命令(堵塞式读取)。
BRPOP 命令的执行流程是:
- 当队列中有数据时,返回
- 当队列中没有数据时,自动堵塞,直到队列中有数据,返回
BRPOP 通过长轮询的方式使消费者能够及时感知新消息的到来,同时避免了多次请求,使用 BRPOP 命令代替 RPOP,能够有效地节省 CPU 开销。
3. 防止消息重复
为了防止消息的重复,容易想到的做法是:
在客户端记录已处理过的消息,接收到消息时,首先判断是否已经处理。
具体做法是:
首先,我们需要唯一标识某个消息,这是因为需要区别 “相同内容的消息” 和 “相同的消息” 这两种情况。由于 List 本身不会为消息生成 ID 号,同时 List 的元素是字符串,因此应该让生产者程序在发送消息时自行生成一个唯一的 ID 号,并且将 ID 号与消息内容拼接在一起组成消息放入 List 中
1
ID号:消息内容其次,我们需要在客户端中记录已处理过的消息。由于 List 本身并不提供这一功能,因此我们需要在消费者程序中自行记录已处理过的消息。同时,为了减少存储 “已处理消息” 带来的空间占用,应该采用只存储 ID 号的方式
4. 保证消息可靠性
在消息队列中读取消息时,有两种做法:
- 使用 RPOP、BRPOP 命令读取消息并从队列中删除消息
- 使用 LINDEX 命令,只读获取队列中的数据
两种做法都有各自的问题,其中:
- 第一种做法无法保证消息可靠性,假如消息被读取后处理失败,将无法重新获取该消息
- 第二种做法时,消息可能被多个消费者重复读取,导致重复消费
一般而言,我们采用第一种做法,并引入额外的机制保证消息可靠性。
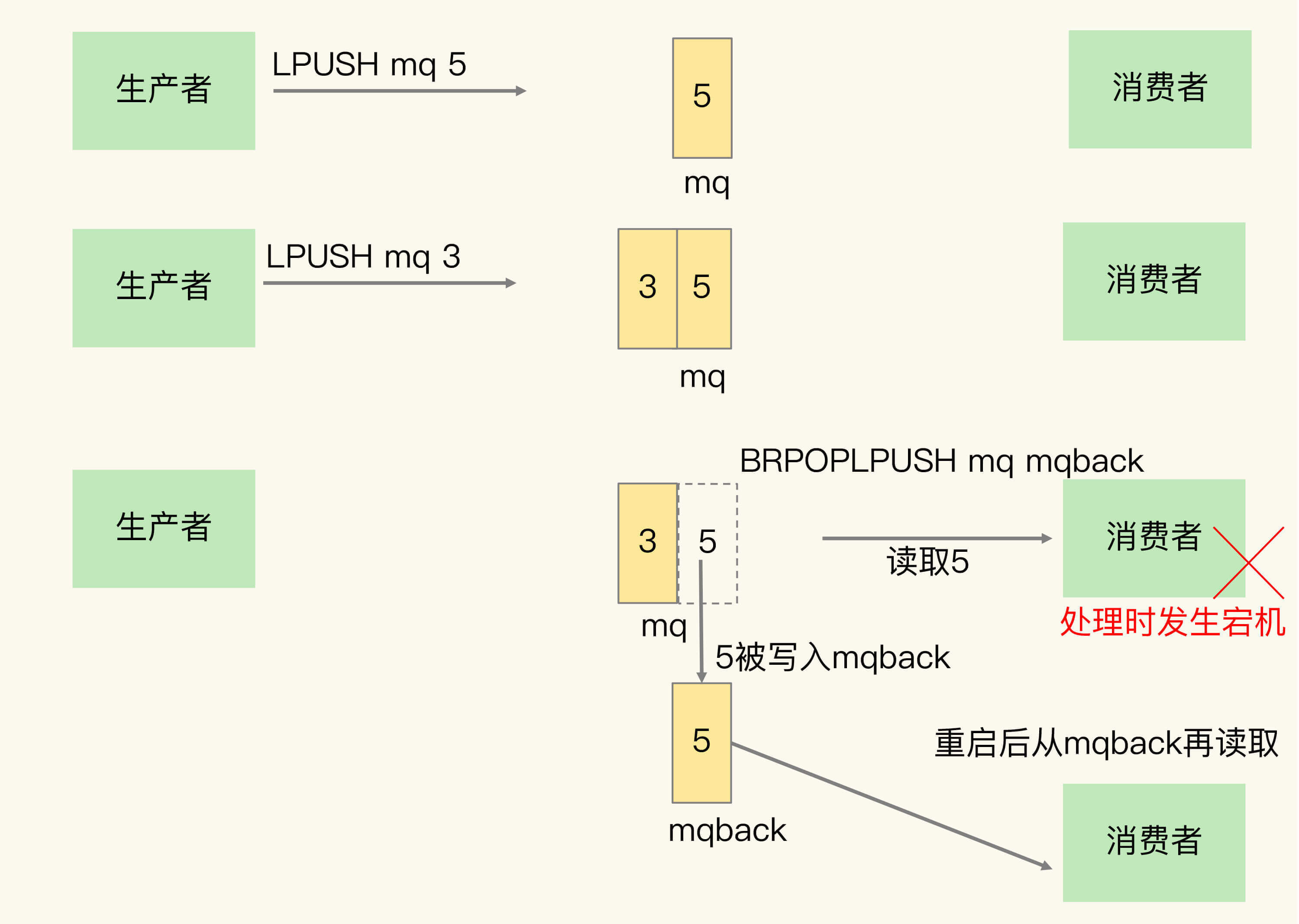
List 类型提供了 BRPOPLPUSH 命令,该命令的作用是:从一个队列中读取元素,并将其放入另外一个 List 中。
因此,我们可以维护另外一个 “备份 List”,让消费者通过 BRPOPLPUSH 从消息队列中读取元素。如果消费者读取了消息却未能正常处理,可以从备份 List 中重新读取消息并处理。
5. 重复消费的支持
基于 List 的消息队列有一个致命的问题,一个消息只能消费一次。
某些场景下,我们希望一个消息被消费多次。
例如一个新订单生成时,通知商家发货、提升用户积分 ···,这些操作都应该由不同的下游子系统进行,它们应该消费同一个消息并做操作
一种可能的方案是:同时使用多个 List,有新消息时向每个 List 放入消息,每个子系统订阅一个 List。
这样的做法有两个缺点,
- 一是性能较差,消息被重复投递
- 二是违背了生产者与消费者解耦的原则,生产者需要知道下游有哪些消费者,以便向队列中投递消息
三、基于订阅的消息队列
1. 订阅
具体请看:
2. 基于订阅的消息队列的缺陷
- 订阅的消息是瞬时的,并不会在服务端持久化保存,如果推送时客户端断连,会导致错失消息
- 订阅中,Redis 会按照消息生产速度推送消息,而不管消费者的处理能力如何,如果消费者处理能力不足,则消息会在 Redis 的 client buf 中堆积,进而导致连接断开、Redis 宕机
三、基于 Stream 的消息队列
1. 说明
Stream 是 Redis 5.0 新增的数据类型,专门为消息队列设计。
2. 结构
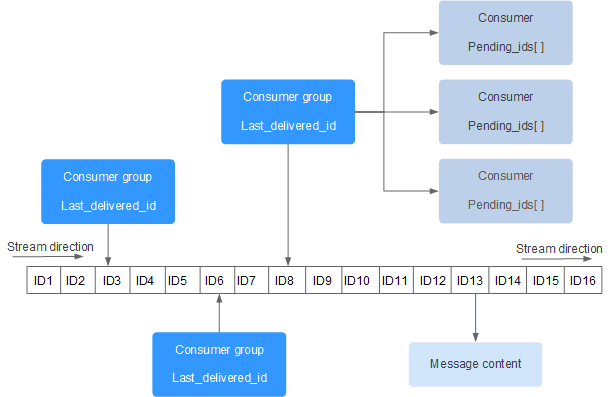
每一个 Stream 都是一个列表,列表中依次存放着每一个消息
每一个消息都有一个由 Stream 生成的递增的唯一 ID
ID 也可以自行决定,但需要保证其递增性
消费组负责读取消息,它由多个消费者组成
- 同一个消费组内的消费者属于竞争关系,不能读取同一条消息
- 不同的消费组相互独立,可以读取同一条消息
- 消费组读取消息时,只能顺着 Stream 方向读取,不得重复读取
每一个消费组会维护一个 Last_delivered_id(已读取 ID),用于标识该消费组最后读取的消息
每一个消费者会维护一个 Pending_ids(等待 ID 列表),用于存储已读取但还未确认消费完成的消息 ID
- 假如消费者宕机,待它重新上线后可以凭借该列表继续处理消息
- 如果消费者彻底宕机后,可以通过
XCLAIM实现消息的转移
3. 阻塞式读取
Stream 支持通过 XREAD 命令的 block 配置项实现堵塞式读取。
4. 基于 Stream 的消息队列的缺陷
- 消息队列的一个重要功能是削峰,队列中可能需要堆积大量的消息,而由于 Redis 基于内存,数据堆积的成本比基于磁盘的消息队列磁盘更高
- Stream 虽然通过确认机制保证消息的可靠性,但由于 Redis 的数据需要从内存持久化至磁盘,因此不可避免地可能因为持久化的问题丢失消息,消息的可靠性无法完全保证
参考
- Redis
- Redis 教程 | 菜鸟教程
- Redis数据库学习教程(快速入门版)
- Redis 核心技术与实战
- Redis消息队列发展历程