Redis 主从模式
本文将介绍 Redis 中的主从模式。
一、主从模式
Redis 的主从模式如图所示:
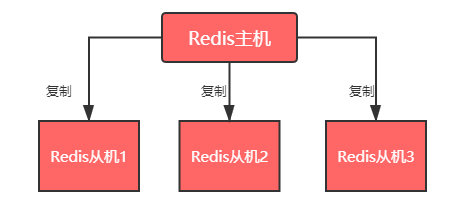
- 主机负责读和写(主要是写),从机负责读(不准写)
- 主机会持续将数据同步给从机
- 在写入少、读取多的情况下,这种模式可以大幅减轻主机的工作压力
- 主机和从机都具有完整的数据,提供了数据的多个备份
二、配置
1. 说明
在主从模式中,需要进行配置的是从机。
即从机需要配置它属于哪一个主机,而主机并不需要额外配置。
2. 配置方式
(1) 命令配置
更加灵活,但每次重启后都需要重新配置
成为某个 Redis 服务的从机:
1 | |
不再作为从机:
1 | |
(2) 配置文件配置
每次启动都会自动进行从机的配置,但是灵活性更差
修改配置文件如下:
1 | |
三、主从同步
1. 初次同步
(1) 说明
当从机被指派 “附属于” 主机时,两个节点之间需要进行初次数据同步。
(2) 具体流程

第一阶段:主从库建立连接、协商同步
从库给主库发送
psync ? -1命令,表示要进行数据同步1
psync runID offset- runID:每个 Redis 实例启动时自动生成的唯一 ID,用于唯一标识实例
- offset:写入位置
由于从库并不知道主库的 runID,因此设为 ?;
offset 设为 -1,表示第一次复制
主库收到 psync 命令后,会用 FULLRESYNC 命令将主库 runID 和 offset 发送给从库
从库接收 FULLRESYNC 命令,保存主节点信息
第二阶段:主库发送所有数据,从库接收数据并加载
- 主库执行 bgsave 命令,生成 RDB 文件,将其发送给从库
- 从库接收文件,清空当前数据库,加载 RDB 文件
第三阶段:主库发送新写命令,从库接收命令并重演
- 在主库生成 RDB 文件的过程中,可能有新的写操作被执行,主库会在内存中用专门的 replication buffer 记录此过程中的所有写操作,并将其发送给从库
- 从库接收修改操作后执行,从而实现了主从库的同步
(3) 性能消耗
在主从库的初次同步中,对于主库而言,有这两个影响性能的操作:
- 生成 RDB 文件:
fork()操作会堵塞主线程,影响正常请求的处理 - 传输 RDB 文件:文件的传输会占用网络带宽
如果从库很多,并且都要和主库进行初次同步,这将给主库带来非常大的性能压力。
可以通过 “主 - 从 - 从” 模式解决这一问题,即从库不再都和主库连接,而是和其它从库连接。
2. 持续同步
一旦主从库完成了初次同步,它们之间便会一直维护一个网络连接,主库会将后续的写命令同步给从库,这个过程也被称为 “基于长连接的命令传播”。
3. 常见问题
(1) 为什么初次同步不使用 AOF?
RDB 文件是经过压缩的二进制数据,相对更小;
而 AOF 文件是对写操作命令的记录,相对更大
在从库加载文件时,RDB 文件可以直接解析还原,速度更快;
AOF 文件需要依次重放每个命令,这个过程需要冗长的处理
(2) 持续同步期间网络断连会怎么样?
如果网络断连,主从库之间的长连接将会断开,从库的数据自然也就没有办法和主库保持一致,这时候应该如何解决?
在 Redis 2.8 之前,主从库需要重新同步,开销非常大
在 Redis 2.8 之后,支持增量同步,避免了重新同步
主库会维护一个 repl_backlog_buffer 环形缓冲区,将所有的命令存储于以循环队列中。主库会记录自己的写入位置,从库会记录自己的读入位置。
具体做法是:
- 当主从库连接恢复之后,从库会首先给主库发送 psync 命令,说明自己的写入位置(offset)
- 主库接收到 psync 命令后,会判断读入位置是否存在于循环队列,
- 如果不存在(读入位置已经被循环队列覆盖),则执行初次同步
- 如果存在,则执行持续同步
(3) 为什么主机应该开启持久化?
假如主机未开启持久化且开启了自动重启,当主机崩溃以后,它将自动重启且因为没有初始化而数据清空,此时主从同步将导致从机上的数据也被清空。
四、主从模式的坑
1. 主从数据不一致
主从数据不一致,是指客户端从从库中读取到的值和从主库中读取到的值并不一致。这是因为主从同步是异步进行的,无法保证主库和从库的数据始终同步。
主从数据不一致没有解决方案,只有缓解方案,可以:
保证主从库间网络连接状况良好,避免将主从库部署在不同的机房,避免将网络通信密集的应用与 Redis 主从库部署在一起
开发一个外部程序监控主从库间的复制进度,当主库与某个从库的差值过大时,直接禁用该从库
可以通过
INFO replication命令查看master_repl_offset主库进度和slave_repl_offset从库进度
2. 过期数据删除问题
Redis 数据过期后不会立即删除,而是 “等待时机” 删除,具体的做法:
- 惰性删除策略:当数据被读写时,检查过期时间,如果过期则删除
- 定期删除策略:每隔一段时间随机选出一定的数据,将其中过期的数据删除
如果读请求发给主库,惰性删除策略将被触发,当数据过期时将数据删除,返回为空;
如果读请求发给 Redis 3.2 之前的从库,由于从库不能执行删除操作,因此将过期数据返回;
如果读请求发给 Redis 3.2 之后的从库,虽然从库不能执行删除操作,但 Redis 会返回空值,避免读到过期数据。
3. 过期时间滞后问题
Redis 设置过期时间的命令一共有 4 个,如下:
- EXPIRE:将过期时间设为 n 秒后
- PEXPIRE:将过期时间设为 n 毫秒后
- EXPIREAT:将过期时间指定为秒时间戳
- PEXPIREAT:将过期时间指定为毫秒时间戳
如果设置过期时间时使用 EXPIRE / PEXPIRE 命令,由于主从同步的延时,从库执行该命令的时间将会晚于主库,从而导致从库上数据的过期时间比主库晚。
4. 主机假死引发的数据丢失
(1) 说明
假设采用哨兵模式进行主从切换,试想这样一个场景:
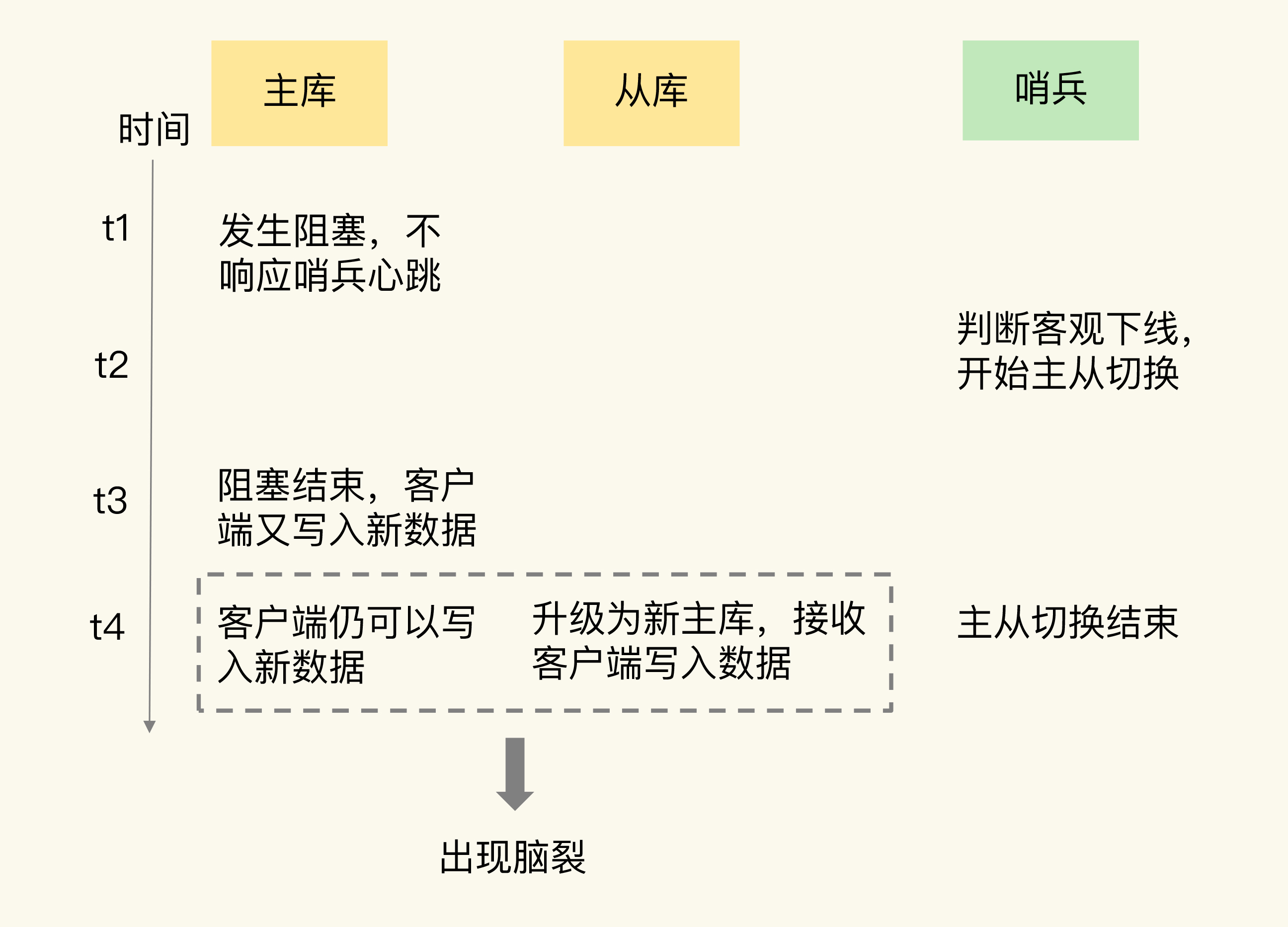
- 原主机与客户端连接,正常处理请求
- 主机发生假死,无法处理请求;原主机被哨兵判定下线
- 哨兵选取新主机,开始主从切换
- 原主机假死结束, 继续处理请求;此时主从集群将有两个主库
- 主从切换仍在继续进行中,要求原主机执行
slave of命令,该命令将清空原主机的数据,导致主从切换期间的新写入丢失 - 主从切换结束
(2) 解决方案
Redis 有两个配置项:
min-slaves-to-write:主库处理请求前提是至少能连接 n 个从库min-slaves-max-lag:主库处理请求的前提是主从库进行数据复制的 ACK 消息延迟不得超过 n 秒
一般将两个配置项搭配使用,设置 min-slaves-to-write 为 总从库数 / 2 + 1,设置 min-slaves-max-lag 为 10 ~ 20 秒。
参考
- Redis
- Redis 教程 | 菜鸟教程
- Redis数据库学习教程(快速入门版)
- Redis 核心技术与实战