MySQL 缓冲池
为了加快数据库的整体性能,InnoDB 使用了 “缓冲池 Buffer Pool” 技术。
一、什么是缓冲池?
InnoDB 存储引擎将数据存储于磁盘中,为了弥补 CPU 速度和磁盘速度之间的鸿沟,InnoDB 使用了缓冲池技术。
简单来说,缓冲池就是一块内存区域,以 “缓冲” 的方式弥补磁盘速度较慢对数据库性能的影响。
二、缓冲池的工作方式
加速读:
执行读取操作时,判断缓冲池中是否有所需的页,
- 如果有,直接读取缓冲池中的页
- 如果没有,从磁盘中读取并放置到缓冲池中
加速写:
执行写入操作时,需要同时修改聚簇索引和多个二级索引,对于每个索引,需要:
判断缓冲池中是否有对应的页,
如果有,修改缓冲池中的页,异步刷新到磁盘
如果没有,
判断是否可以使用 change buffer,
如果可以,将变更记录在 change buffer 中,待合适的时候将变更同步到数据页
如果不可以,读取数据页至缓冲池,修改缓冲池中的页,异步刷新到磁盘
三、加速读
1. 初始化过程
- 首先向操作系统申请内存空间
- 将内存空间划分为若干对控制块和缓存页
2. 控制块
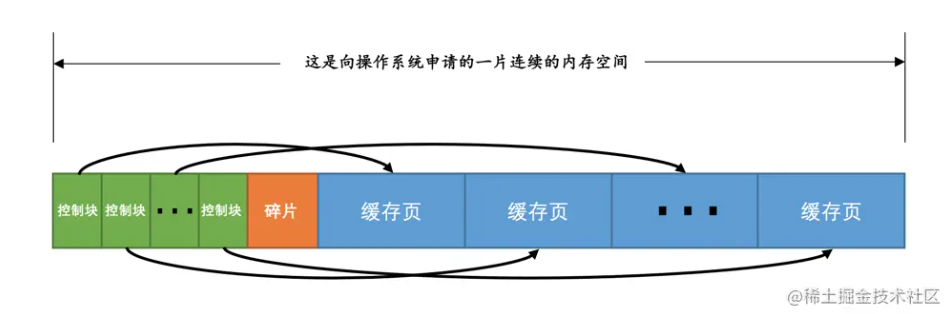
为了更好地管理缓冲池中的缓存页,每一个缓存页都会对应生成一个控制块,控制块中包含着与对应页有关的控制信息(表空间编号、页号、缓存页地址、链表节点信息、锁信息、LSN 信息等)。
3. free 链表
页从磁盘中读取后需要找到缓冲池中的存放位置,此时我们希望找到一个空闲的缓存页。
为了方便地获取空闲的缓存页,InnoDB 会将空闲的缓存页对应的控制块串联形成一个双向链表,这个链表被称为 free 链表。
因此,每当从磁盘中加载一个页,就从 free 链表中找到一个空闲的缓存页,向缓存页填入数据、向控制块填入控制信息、将控制块从 free 链表中移除。
4. hash 避免重复缓存
为了页的重复读取和缓存,以 表空间名 + 页号 为 key,以缓存页为 value,维护一个哈希表。当需要访问某个页的数据时,先从哈希表中尝试获取缓存页,当没有时,才到磁盘中加载。
5. LRU 链表
(1) 缓存页的释放问题
考虑这样一个问题,当缓冲区已经没有多余的空闲缓存页,但此时仍希望读入新的页,应该怎么做?
此时便需要释放部分缓存页,以腾出空间给新的缓存页使用,被释放的缓存页如何选取便是我们需要考虑的问题。
(2) 简单的 LRU 链表
具体请看:
(3) LRU 链表的优化
在 InnoDB 中存在两个会影响 LRU 正常运行的东西:
- 预读:InnoDB 会自动推测接下来可能读取的页面,将它们预先加载到缓冲区中;这会导致缓冲区加载了不一定被使用的页,影响 LRU 链表的排序
- 全表扫描:如果进行全表扫描,则意味着需要访问该表所出的所有页,这可能造成大量页面的访问;这会导致缓冲区载入很多只会被访问一次的页,LRU 链表被 “洗牌”
针对这两个问题,InnoDB 给出了以下解决方案:
将 LRU 链表分为热、冷两截,分别表示使用频率高和低的缓存页
1
头节点 热1 热2 热3 热4 冷1 冷2 冷3当页面初次加载到缓冲区时,该缓冲页对应的控制块不会直接被放置到 LRU 链表的头部,而是会被放置到 “冷区” 的头部
对于处在 “冷区” 中的缓存页,会在对应的控制块中记录最近访问时间,当且仅当访问间隔小于规定的最小访问间隔时,该存储页才可以被移动至 “热区”
四、加速写 - 直接写数据页
1. 脏页
如果修改了缓冲区中的某个缓存页中的数据,则它与磁盘上的页将变得不一致,这样的缓存页被称为 “脏页”。
2. flush 链表
对于 “脏页” 的处理,有一种最简单的方式,就是每发生一次修改就立即同步到磁盘上。这样虽然能够尽可能保证数据的一致性,但频繁的磁盘 IO 将会严重影响性能。
因此,我们会先将 “脏页” 记录起来,待到 “某个时候” 再将它们同步到磁盘上。
InnoDB 会将所有 “脏页” 对应的控制块串联形成一个双向链表,这个链表被称为 flush 链表。
3. 脏页刷新至磁盘
正常方式下,脏页刷新到磁盘有以下两种方式:
- 单独线程、异步;定时;逆序扫描 LRU 链表中的 “冷区”,将一部分页面刷新至磁盘
- 单独线程、异步;定时;顺序扫描 flush 链表,将一部分页面刷新至磁盘
当系统繁忙时,可能会出现 “希望读入新页,但缓冲区没有空间,LRU 链表尾部也没有可以直接释放的未修改页面” 的情况,此时可能会进行页的 同步 刷新。
五、加速写 - change buffer
1. 什么是 change buffer?
change buffer 是一个变更记录的缓冲区,通过它,可以在不读取数据页的情况下 “完成对数据的修改”。
在 MySQL 5.5 之前,只有插入缓存(insert buffer);
在 MySQL 5.5 之后,插入缓存被扩展,现在它叫做修改缓存(change buffer),可以优化 INSERT、DELETE、UPDATE。
2. 工作方式
记录变更:将变更记录在 change buffer 之中
应用变更(merge):将数据页读入缓冲池中,执行 change buffer 中的相关操作
merge 触发的时机有:
- 访问数据页
- 后台线程定期 merge
- 数据库正常关闭
3. 好处
减少磁盘 IO 和内存占用。
4. 使用条件
对于唯一索引,所有更新操作都需要判断该操作是否违反唯一性约束,这个判断需要将数据页加载进缓冲池中,因此没有再使用 change buffer 的必要。
因此,change buffer 不能用于聚簇索引、唯一索引,change buffer 能够用于普通索引。
5. 使用场景
对于写多读少的场景,使用 change buffer 可以减少磁盘 IO 和内存占用,使用效果最好。
反之,假设总是写入后立马查询,在这种情况下,在 change buffer 中记录操作后又需要立刻进行 merge,磁盘 IO 和内存占用并不会减少,反而增加了 change buffer 的维护代价。
参考
- MySQL 技术内幕
- MySQL 实战 45 讲
- MySQL 是怎样运行的:从根儿上理解 MySQL