Redis 数据淘汰策略
本文将介绍 Redis 中的数据淘汰策略。
一、为什么要淘汰数据?
缓冲的一个重要作用是:使用内存缓存数据,提升应用的响应速度。
在实际的场景下,一个应用往往有大量的数据,将这些数据都放进内存中是不现实的,原因有:
- 内存的价格较贵
- 大多数数据的访问频次较低,缓存 “高频数据” 是更合适的选择
因此,缓存空间容量必然远远小于数据库空间容量。
在这种情况下,有限的缓存空间会在缓存工作过程中不可避免地被写满,此时便需要引入 缓存数据的淘汰机制 。
二、缓存空间容量设置
对于不同的应用,常被访问的数据占总数据的比例所有不同。
一般来说,将缓存空间容量设置为数据库空间容量的 15% ~ 30%。
三、Redis 的淘汰策略
1. 8 种淘汰策略
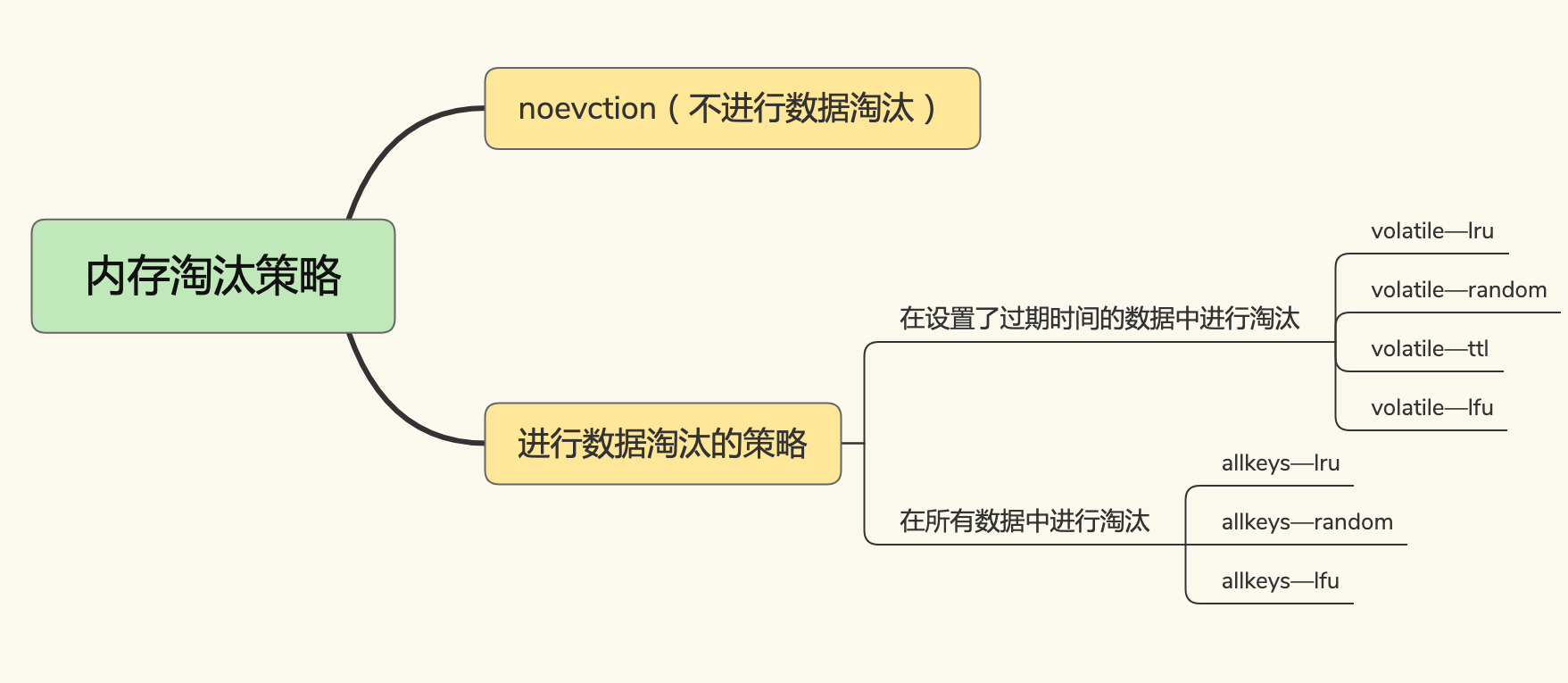
Redis 4.0 之前有 6 种淘汰策略,4.0 之后又新增了 2 种,因此一共有 8 种淘汰策略。
- noeviction:默认策略;不会进行数据淘汰;如果内存空间被占满,拒绝写请求
- volatile-lru:在设置了过期时间的数据中进行淘汰;使用 LRU 算法删除
- volatile-random:在设置了过期时间的数据中进行淘汰;随机删除
- volatile-ttl:在设置了过期时间的数据中进行淘汰;根据过期时间的先后进行删除
- volatile-lfu:在设置了过期时间的数据中进行淘汰;使用 LFU 算法删除
- allkeys-lru:在所有数据中进行淘汰;使用 LRU 算法删除
- allkeys-random:在所有数据中进行淘汰;随机删除
- allkeys-lfu:在所有数据中进行淘汰;使用 LFU 算法删除
2. LRU 算法
LRU 算法按照最近最少使用原则,将最近最不常用的数据删除。
可参考:
原始的 LRU 算法需要用维护一个链表,这会带来额外的空间占用,并且数据被访问时也会产生链表移动操作,这会降低 Redis 的性能。
因此,Redis 对 LRU 算法进行了简化,如下:
Redis 会记录每个数据最近一次被访问的时间
当需要淘汰数据时,随机选出 N 个数据,比较这些数据的最近被访问时间,按照时间删除数据
Redis 提供了 maxmemory-samples 配置参数,用于配置 N 的个数
3. LFU 算法
LRU 算法有一个漏洞:假如有大范围的数据扫描,则这些被扫描覆盖的数据将拥有统一的较新的过期时间,这批数据将会在缓存中一起驻留并淘汰其它数据,直至更新的数据将其挤出。
因此,Redis 从 4.0 版本开始增加了 LFU 算法,它在 LRU 的基础上增加了对数据被访问次数的判断。当要淘汰数据时,淘汰访问次数最低的数据,当有多个数据访问次数一样低时,淘汰最近被访问时间最早的数据。
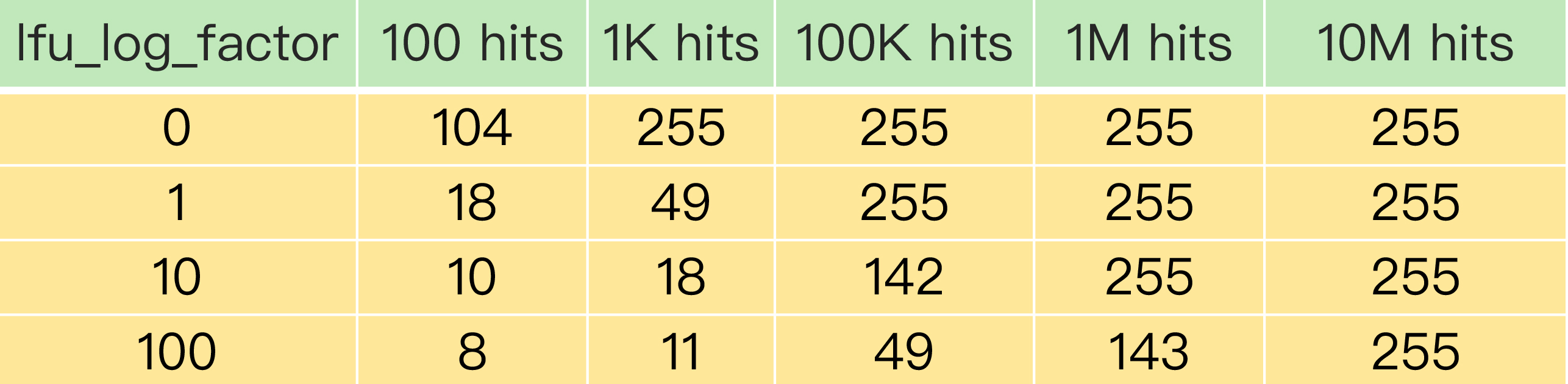
Redis 用 24bit 大小的 lru 字段存储数据被访问信息,其中 16bit 存储时间戳,8bit 存储被访问次数,因此被访问次数的最大值是 255。
如果被访问次数很快便被加至最高值,大量数据的被访问此数值相同,LFU 算法便无法很好地决定应该被淘汰的数据。
因此,Redis 引入了 “延缓因子 lfu_log_factor”,数据被访问后需要做计算,当且仅当
1 / (当前被访问次数 * lfu_log_factor + 1)大于 0 ~ 1 之间的随机数时,被访问次数才自增。通过这种方式,很好地延缓了被访问次数的增长。
4. 淘汰策略选择建议
- 优先使用 allkeys-lru 策略
- 如果应用中数据的访问频率相差不大,没有明显的冷热数据区分,建议使用 allkeys-random
- 如果应用中存在高频且不可被淘汰的数据(例如每个用户都可见且每个用户都必须看见的置顶信息),可以将这些数据设为永不过期,并使用 volatile-lru 策略
参考
- Redis
- Redis 教程 | 菜鸟教程
- Redis数据库学习教程(快速入门版)
- Redis 核心技术与实战