Redis 穿透、击穿、雪崩
本文将介绍 Redis 中可能出现的穿透、击穿、雪崩及其解决方案。
一、正常流程
在加入缓存的情况下,正常工作流程是这样的:
- 接收查询请求
- 尝试从缓存中获取数据
- 如果缓存中有,直接返回
- 如果缓存中没有,则从数据库中获取,将其缓存,返回结果
二、缓存穿透
1. 什么是缓存穿透?
在正常查询流程中,如果某项数据未在缓存中找到,则会尝试从数据库中获取,将结果返回并缓存。
存在这样一个场景:某个查询的结果注定为空,后端接收请求后尝试从缓存中获取,发现缓存中没有后向数据库查询,数据库查询后返回 null,Redis 的一般策略决定了它不会缓存此空数据。因此,每一次相同查询都需要访问数据库。
在这种情况下,每次对 “空数据” 的查询都会 “撬开” 缓存、访问数据库,这便是缓存穿透。
2. 解决方案
(1) 缓存空对象
即使查询结果为空,也将其缓存。
(2) 增加校验
对参数做校验,直接拒绝非法请求。
2
3···/list?pageNum=-1&pageSize=10
// err pageNum不得小于1
(3) 布隆过滤器
具体请看:
布隆过滤器是一个数据结构,能够用于 “预估” 元素是否存在,它的优点是高效、快速,缺点是并不完全准确。
具体来说,
- 布隆过滤器维护了一个位数组
- 当向其中放入元素时,通过若干个哈希函数计算出若干个索引值,将位数组中的对应位置赋值为 1
- 当判断元素是否存在时,通过若干个哈希函数计算出若干个索引值,判断这些索引值对应的数组项是否全部为 1
使用布隆过滤器来应对缓存穿透时,有两个核心操作:
- 数据预热: 预先将所有可能的查询 key 加入布隆过滤器中
- 存在性校验:接收到查询请求时,首先判断 key 是否存在,存在时才允许查询
数据预热:
将所有的 id 存入布隆过滤器中
2
3
4List<User> users = userMapper.selectList(userQueryWrapper);
for (User user:users) {
bloomFilter.put(user.getId());
}存在性校验:
2
3
4
5if (bloomFilter.mightContain(id)) {
···查询···
} else {
···拒绝···
}
三、缓存击穿
1. 什么是缓存击穿?
缓存击穿通常发生在高并发的场景下的热点数据过期失效时。
当请求发现数据不存在于缓存时,会去数据库查询数据,将结果放入缓存并返回。向数据库查询需要一定的时间,这段时间内,缓存中的数据始终是缺失的,如果瞬时有大量请求,这些请求都会去数据库查询,给数据库带来巨大的压力。
2. 解决方案
(1) 永不过期
对于不轻易改变且访问量较大的数据,可以设为永不过期。
(2) 加锁
向数据库查询之前,需要先获取锁,从而确保只有一个请求落到数据库。
四、缓存雪崩 - 大量击穿
1. 原因说明
即大量缓存击穿同时发生,通常发生在并发量较大且多个缓存同时过期的情况下。
2. 解决方案
(1) 永不过期
略
(2) 加锁
略
(3) 分散过期时间
通过手动设置或随机设置的方式,分散过期时间,避免缓存大量同时过期。
(4) 服务降级
暂缓对非核心服务的处理,给核心服务腾出服务器资源。
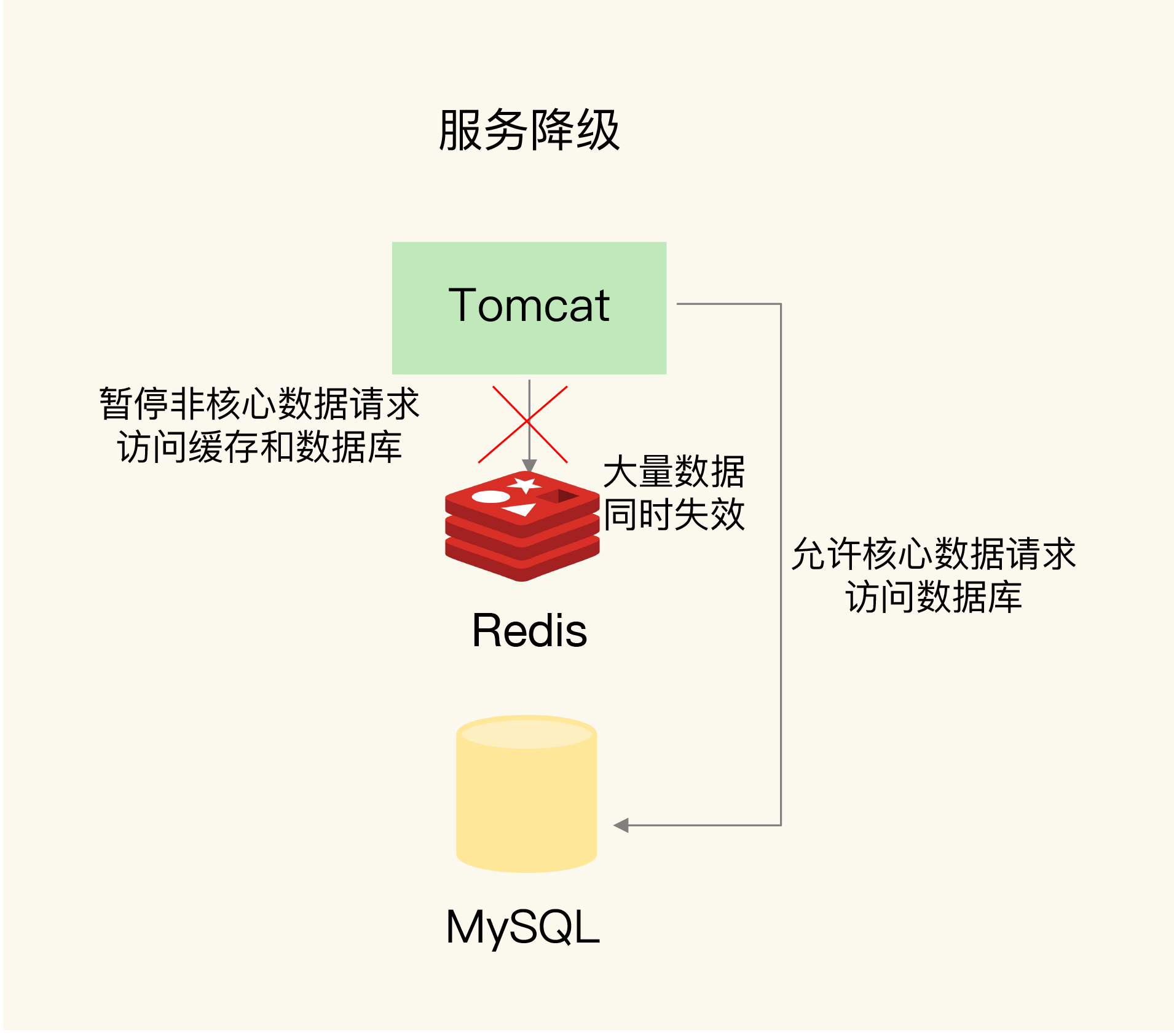
- 如果用户请求的是非核心数据,拒绝访问,返回预定义信息 / 空信息 / 错误信息
- 如果用户请求的是核心数据,正常处理
五、缓存雪崩 - 缓存宕机
1. 原因说明
如果 Redis 实例发生故障宕机,就会导致大量请求堆积到数据库。
2. 解决方案
(1) 搭建集群
可以通过搭建 Redis 集群的方式,避免单一 Redis 节点宕机影响缓存的正常工作。
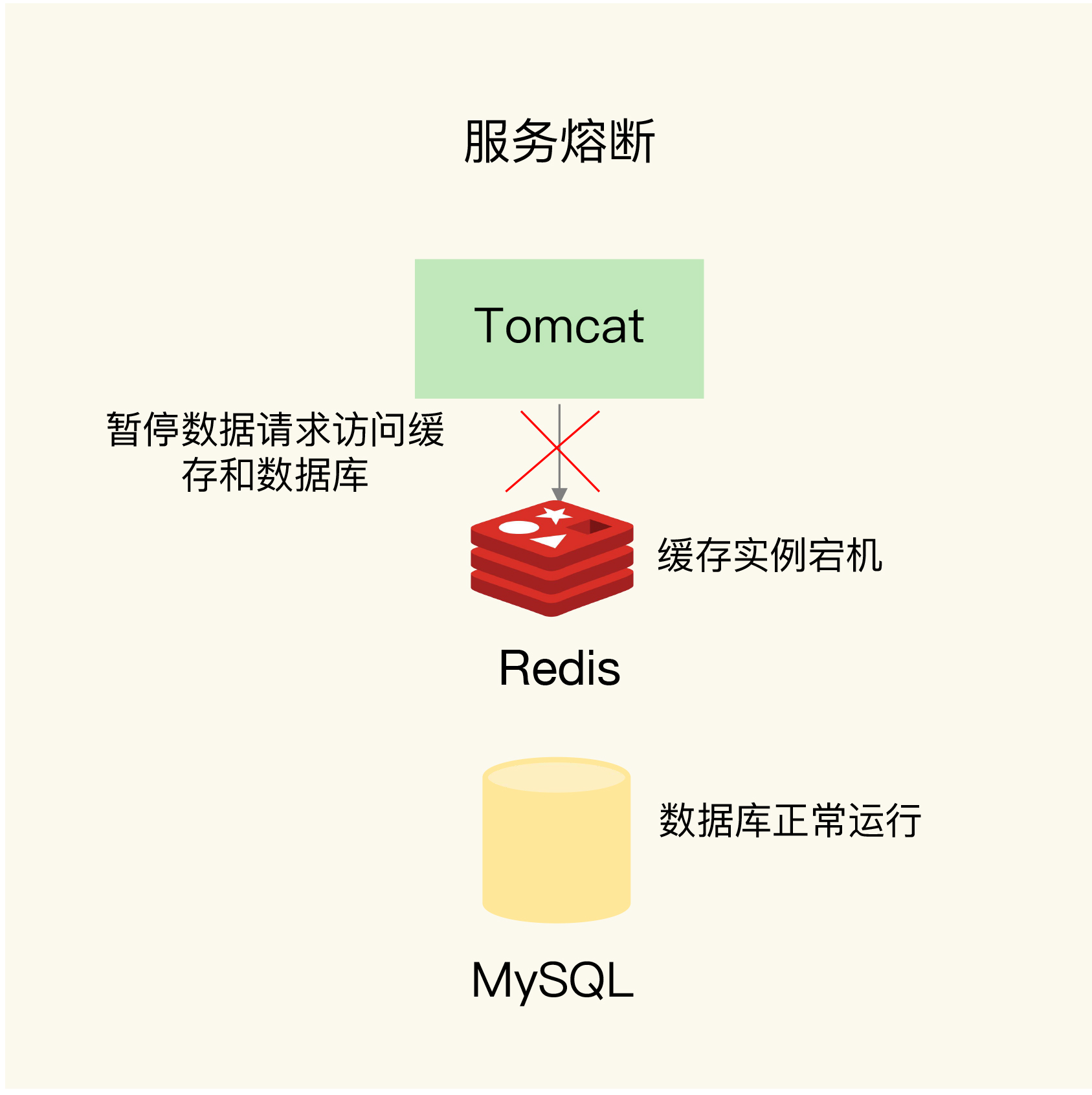
(2) 服务熔断
为了避免继而引发数据库的崩溃,暂停服务。
在实际场景中,可以检测 Redis 和数据库所在服务器的负载指标,当发现 Redis 宕机且数据库所有服务器负载增加时,启用服务熔断机制,暂停应用对数据的访问。
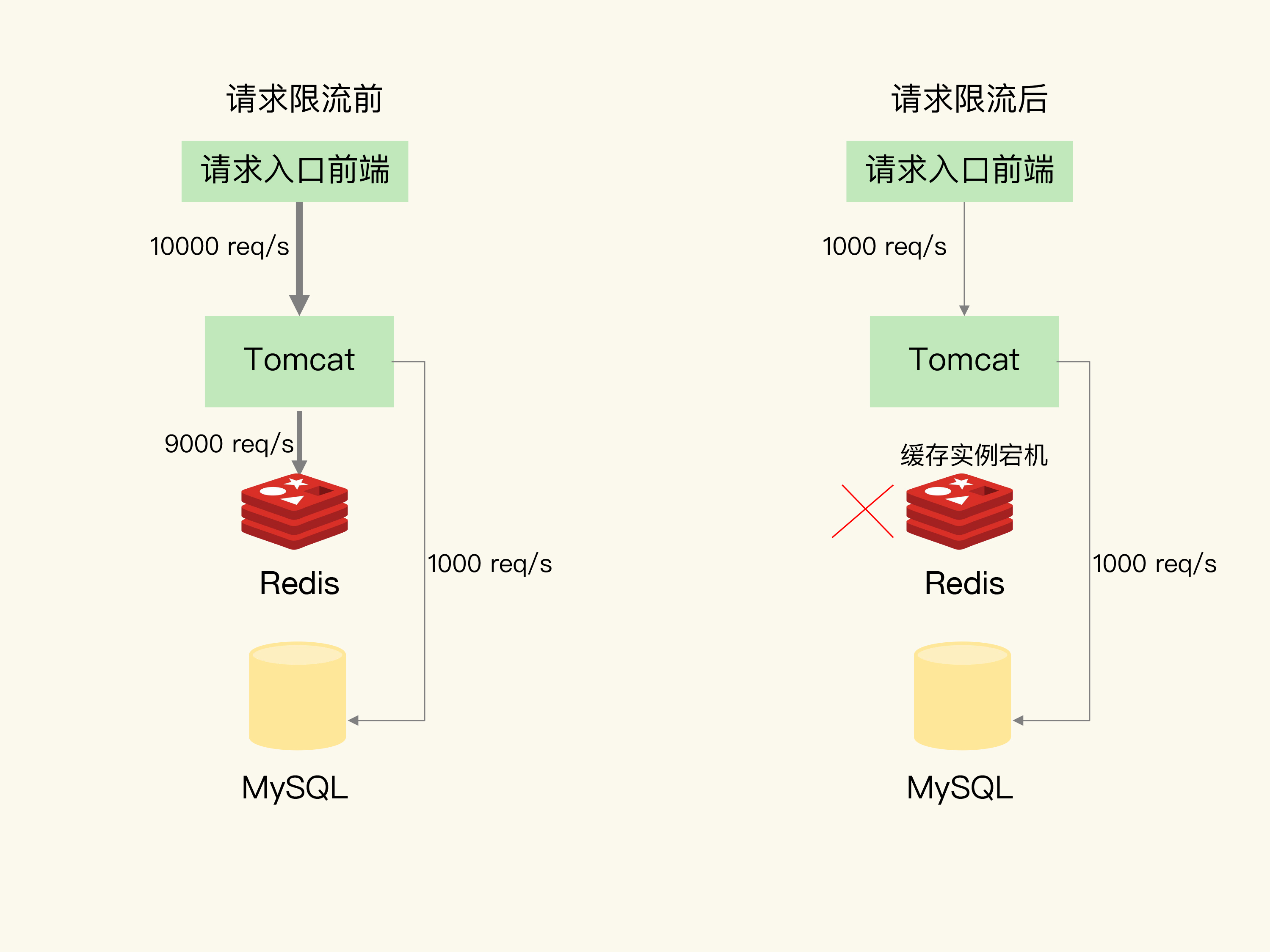
(3) 请求限流
请求熔断虽然可以最大程度上保护数据库,但是也极大地影响了应用的正常运行。
还可以使用请求限流,在保护数据库的同时尽量维持应用的正常运行,具体做法是:在请求入口处控制请求量,只允许一定量的请求进入系统。
参考
- Redis
- Redis 教程 | 菜鸟教程
- Redis数据库学习教程(快速入门版)
- Redis 核心技术与实战