MySQL 三大日志
本文将介绍 MySQL 中的 binlog,二进制日志。
一、binlog
1. binlog 是什么?
- binlog 是 服务层 的日志
- binlog 是 binary log 的缩写,即二进制日志
- binlog 中记载了数据库的变化,包括:新建数据库、新建表、改动表结构、改变数据等
2. binlog 的使用场景
复制:
MySQL 主从模式依赖于 binlog,从库会读取并重做 binlog 中的内容,达到与主库数据一致的目的
恢复:
在现实场景中,数据库中的数据可能被有意或无意地删除,又因为随时做全量备份是不现实的,我们可能会不可避免地损失部分数据。
这时候,binlog 便可以排上用场,只需要恢复全量备份,再执行全量备份至删除数据前的所有 binlog,就可以将数据库恢复至删除数据前的状态
审计:
因为 binlog 中包含数据库的每次改动,因此可以利用它进行 SQL 审计
3. binlog 的格式
基于语句:记录 SQL 语句

可能会造成主从数据库的数据不一致。
例如两个数据库的自增值不同,导致插入的记录的主键不同
基于行:记录语句执行中每一条记录更新前后的值
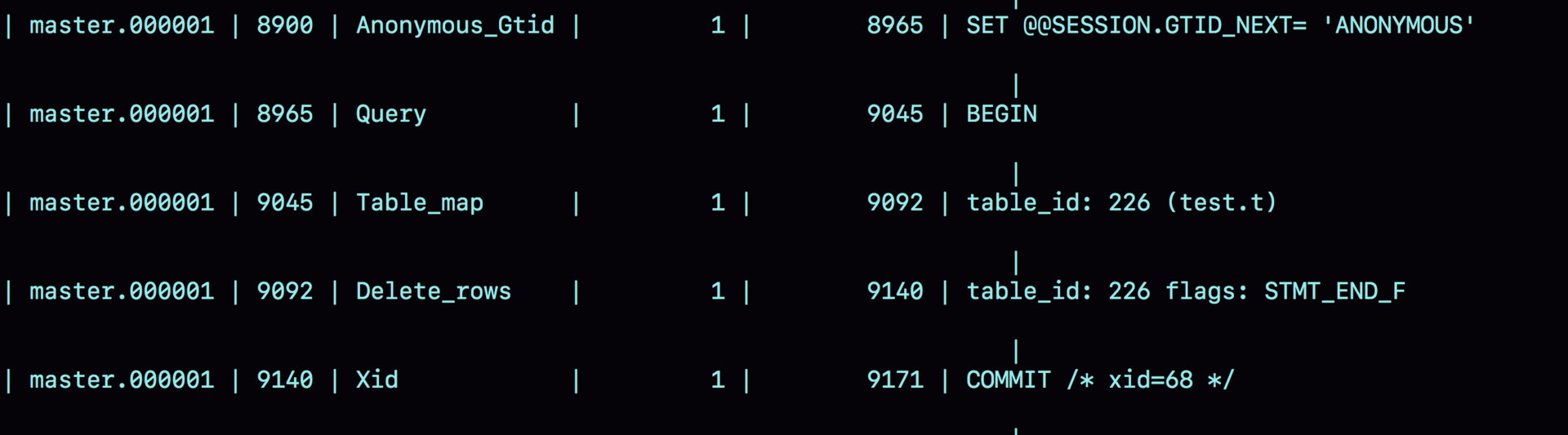
基于行的 binlog 有着占用空间过大的缺点
假设用 delete 语句删除 10 万行数据,则基于语句的 binlog 只需要记录一个 SQL 语句,而基于行的 binlog 需要记录 10 万条记录,这样做会占用极大的空间,并且也会耗费 IO 资源,影响执行速度
mixed 格式:基于语句和基于行的结合,MySQL 会判断语句是否可能造成主从数据库不一致,如果会,用基于语句的格式,否则用基于行的格式
4. binlog 的写入机制
写入逻辑:
- 事务执行过程中,把日志写到 binlog cache 中
- 事务提交时,把 binlog cache 写到 binlog 中
binlog cache 逻辑:
系统分配了一片内存空间,每个线程拥有一块独立的 binlog cache,但是都要最终写入到同一个 binlog 文件中。
write、fsync 逻辑:
write 和 fsync 的时机由参数 sync_binlog 控制:
- 为 0 时,只 write 不 fsync
- 为 1 时,每次都 write 并 fsync
- 为 N 时,累计 N 个事务进行一次 fsync
一般情况下,将其设置为 100 ~ 1000 之间的某个数值。
二、redo log
1. redo log 是什么?
redo log 是 InnoDB 特有的
redo log 又被称为重做日志
假设系统崩溃时有被改动的 “数据页” 未刷回磁盘,改动便会丢失。可以根据 redo log “重做” 操作以恢复改动,这便是 redo log 名字的由来。
redo log 是持久性的保证
事务有 “持久性” 这一特征,其执行结果应该被持久存储。写入操作会首先改动缓冲池中的数据,在适当的时候才会刷回磁盘,存在崩溃导致执行结果丢失的可能。通过 redo log,将事务的改动记录,从而可以保证持久性。
redo log 记录事务对某个数据页的某个地方做了某些修改
例如:
1
将第 0 号表空间的 100 号页面的偏移量为 1000 处的值更新为 2每次事务提交时,InnoDB 会:
- 记录 redo log,刷新至磁盘
- 更新内存中的数据,稍后刷新至磁盘
2. 先刷新 redo log 的好处
相比于将数据页刷新磁盘,先将 redo log 刷新到磁盘中的好处有:
改动可能涉及多个数据页,数据页刷回时需要将整个页面一起刷回,消耗比较大;
redo log 占用的空间更小,刷新消耗更小
改动可能涉及多个数据页,它们可能分布于不同位置,随机 IO 会影响刷新速度;
redo log 可以被顺序写入磁盘中
3. redo log 格式

各个部分的详细释义如下:
- type:该条 redo log 的类型
- space ID:表空间 ID
- page number:页号
- data:该条日志的具体内容
4. redo log 的写入机制
redo log buffer 中的内容不需要每次写入都持久化到磁盘,只需要保证事务提交时持久化。
如果在事务执行过程中宕机,事务未提交,此时日志丢失反而是正确的
redo log 的写入经过以下几个流程:
写入到 redo log buffer
刷回到 redo log 文件中,刷回时机有:
- 事务提交时,redo log 会被刷回磁盘
- InnoDB 有一个后台线程,它会每隔一秒将 redo log buffer 中的内容写入到 redo log 文件
- 当 redo log buffer 占用的空间达到 innodb_log_buffer_size 的一半时,后台线程会主动 write(但不会 fsync)
- 如果同时有其它事务进行了提交,则它会 “顺便” 将这一事务的 redo log buffer 中的内容写入到 redo log 文件
三、binlog 与 redo log
1. 区别
binlog 是 MySQL 的服务层实现的;
redo log 是 InnoDB 特有的
binlog 是逻辑日志,记录的内容是 “执行了某条 SQL 语句 / 某一行的数据进行了某些改动”;
redo log 是物理日志,记录的内容是 “某个数据页的某个地方做了某些修改”
binlog 将日志写入文件中,可以 “无限写入”;
redo log 空间固定且循环写入
2. 关联
binlog 与 redo log 通过共有的数据字段 XID 关联。
3. 为什么要有 redo log?
binlog 日志会记录数据库的变化,在 MySQL 的设计中,理想的数据修改流程应该是这样的:
- 修改数据
- 在事务提交时记录 binlog
但是,为保证性能,InnoDB 设计了缓冲池,具体见 MySQL 缓冲池。在这样的设计下,如果事务已提交且数据未同步至磁盘,此时发生崩溃重启,数据库中的数据和 binlog 记录的数据将会发生不一致。
因此,InnoDB 额外增加了 redo log,通过它来在崩溃重启后恢复数据。
4. 两阶段提交
(1) 语句执行过程中的 binlog 和 redo log
MySQL 在执行简单 update 时:
- 执行器调用存储引擎完成操作,存储引擎
- 直接操作缓冲池中的数据页,做修改
- 将操作记录存储到 redo log 中,此时 redo log 处于 prepare 状态
- 执行器生成 binlog,将 binlog 写入磁盘
- 执行器调用存储的提交事务接口,存储引擎会将 redo log 改为 commit 状态,并将 redo log 刷回磁盘
(2) 为什么需要两阶段提交?
为了让两份日志之间的逻辑保持一致。
以反证法证明,
- 假设先写 redo log 后写 binlog:如果在 redo log 写完且 binlog 未写完时崩溃,redo log 能够保证数据库的状态最新,而 binlog 中缺失语句
- 假设先写 binlog 后写 redo log:如果在 binlog 写完且 redo log 未写完时崩溃,redo log 无法保证数据库状态最新,而 binlog 中有最新数据的修改记录
因此,应该使用两阶段提交。
四、undo log
1. 什么是 undo log?
- undo log 是 InnoDB 特有的
- undo log 会将数据因修改而产生的各个版本组合成链表
2. 版本链
事务对某一行记录的多次修改会产生多个版本,这些版本在数据库中如何存储和寻找呢?
InnoDB 通过聚簇索引记录保存了记录的 “最新版本”,可以通过主键在其中找到记录的 “最新版本”
InnoDB 通过 undo 日志保存了记录的 “旧版本”,可以通过 “最新版本” 的 roll_pointer 找到由 “旧版本” 组成的 “旧版本链”
“最新版本” 与 “旧版本链” 一起,共同构成了 “版本链”:
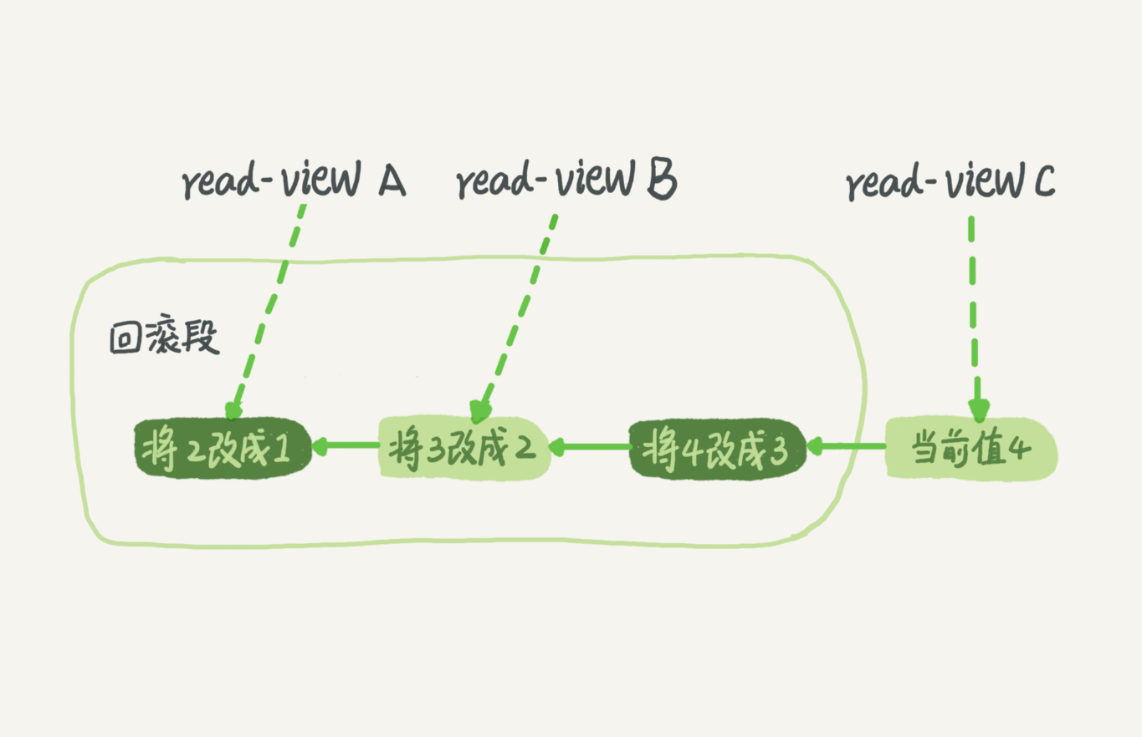
需要注意的是:
- 数据的最新版本存储在数据页中;undo log 存储在类型为 FIL_PAGE_UNDO_LOG 的页面中
- 可以通过数据行的 roll_pointer 获取到对应的 undo log 的地址
3. undo log 什么时候删除?
undo log 不会始终保留,否则链表越来越长将极大占据空间。
当系统中没有比 undo log 更早的 ReadView 时,undo log 不再被需要,系统会自行移除。
4. 为什么不建议用长事务?
长事务意味着其 ReadView 将会持久存在,则 InnoDB 需要为其维护 “很老” 的 ReadView,记录的版本链也会变得很长,这将大量占用存储空间。
5. 作用:保证原子性
事务的 “原子性” 表示事务是最小的执行单位,不可再分,要么执行,要么不执行。假如事务在执行到一半时发生问题导致无法继续执行,这种情况下事务被认为是 “失败的”,应该 回滚 它已进行的操作。
使用 undo log 可以在事务失败后回滚。
6. 作用:保证隔离性
undo log 可以服务于 MVCC,保证事务的 “隔离性”。
参考
- MySQL 技术内幕
- MySQL 实战 45 讲
- MySQL 是怎样运行的:从根儿上理解 MySQL