MySQL count(*)语句
本文将介绍 MySQL 中 count(*) 语句的执行。
一、count(*) 的遍历计算
假如没有过滤条件:
在 MyISAM 中,表的总行数被存在磁盘中某个位置,因此执行 count(*) 时可以直接返回这个数
在 InnoDB 中,执行 count(*) 时,需要将数据一行行读出累积计数
由于 MVCC,即使在同一时刻,不同事务的相同查询的结果也可能是不同的,因此这个数字需要遍历确定
假如有过滤条件:
MyISAM 和 InnoDB 都需要遍历确定数量
在遍历计算的情况下,一个简单的 count(*) 语句可能会花费较多的性能和时间。
二、show table status
在 MySQL 中,show table status 的输出结果中的 TABLE_ROWS 字段会显示表的行数,这个数据是通过采样估算的,官方文档中说明误差可能达到 40% ~ 50%,因此,这条命令中显示的行数不能直接使用。
三、解决方案
1. 缓存保存计数
可以在缓存中保存 count(*) 的计数,并在增、删时维护。
这个方法可能会遇到数据不一致的问题:
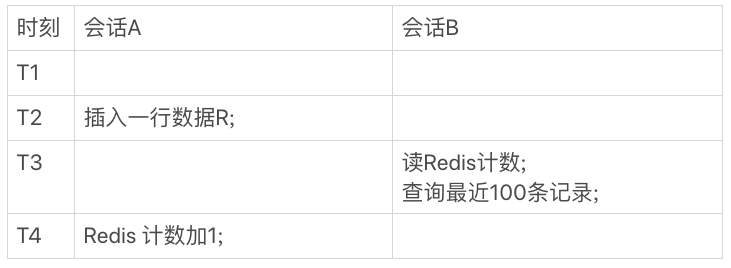
- 会话 A 插入数据
- 会话 B 读取 “旧计数”
- 会话 B 读取数据
- 会话 A 更新计数
会话 B 读取到的数据和计数并不一致
2. 数据库中保存计数
可以在数据库中单独放置一张计数表,在表中保存 count(*) 的计数,并在增、删时维护。
这种方法可以解决数据不一致问题:
- 会话 A 更新计数
- 会话 B 读取计数
- 会话 B 读取数据
- 会话 A 插入数据
- 会话 A 提交
由于 MVCC,在 “可重复读” 下,会话 B 不会读取到会话 A 中的改动,避免了数据不一致的情况

四、count(字段)、count(主键 ID)、count(1)、count(*)
count(主键 ID)和count(1)和count(*)的结果相同,都是满足条件的总行数;count(字段)的结果是满足条件且字段不为 null 的总行数count(主键 ID)会遍历整张表,对于每一行,判断主键不为空,累加计数;count(1)会遍历整张表,对于每一行,判断 1 不为空,累加计数;count(*)会遍历整张表,对于每一行,累加计数按效率的排序:
count(字段) < count(主键 ID) < count(1) ≈ count(*)
参考
- MySQL 技术内幕
- MySQL 实战 45 讲
- MySQL 是怎样运行的:从根儿上理解 MySQL