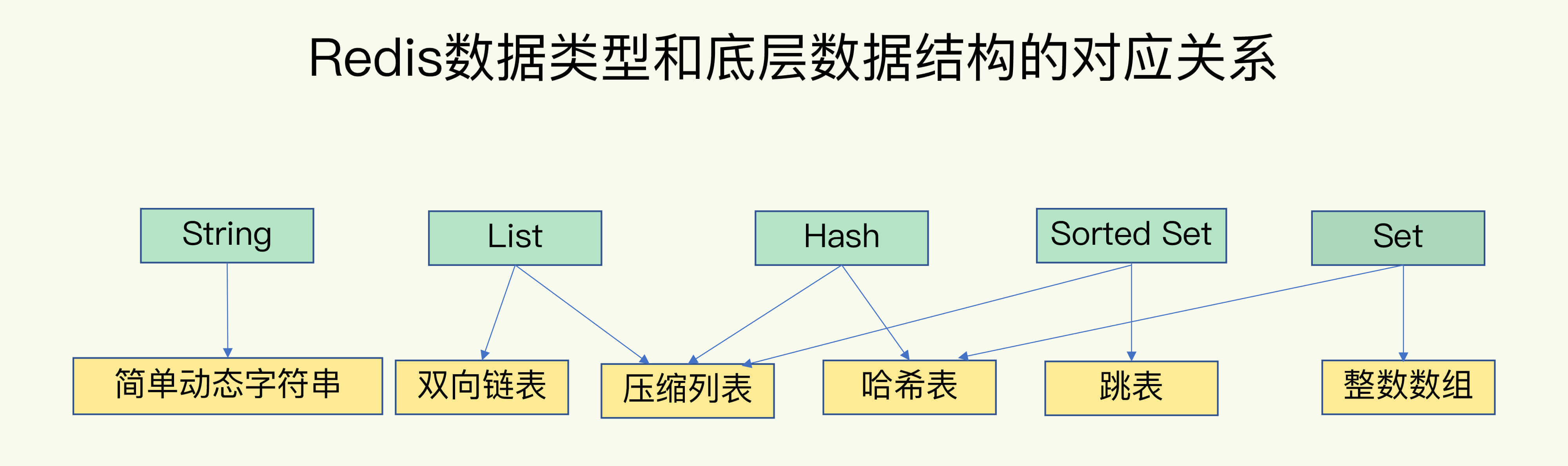
Redis 类型
本文将介绍 Redis 中的五大数据类型及三种特殊数据类型。
一、String
1. 说明
String,字符串,是 Redis 中最基本的数据类型。
2. 底层实现
Redis 使用字符串数组来存储字符串,其结构定义如下:
1 | |
3. 空间分配规则
为了避免频繁的内存分配,Redis 使用了预先分配冗余空间的办法,即每次都为字符串分配大于实际占用的空间。这样,如果对字符串进行小改动时,就不会频繁地进行空间的分配。
当字符串所需空间超出被分配的空间大小时,Redis 会为其扩容,扩容规则为:小于 1MB 时,成倍扩容;大于 1MB 时,每次扩容 1MB。
4. 常用命令
(1) 命令 - 设置
1 | |
(2) 命令 - 设置数值
1 | |
(3) 命令 - 获取
1 | |
二、Hash
1. 说明
Hash 是 field - value 的映射表。
2. 底层实现
- 当存储的数据较少时,使用压缩列表作为底层存储结构
- 当存储的数据较多时,使用哈希表作为底层存储结构
3. 哈希冲突解决
在 Hash 中,通过拉链法解决哈希冲突。
4. 扩容原理
随着 Hash 中的元素越来越多,哈希冲突将会越来越多,进而导致查询效率由 o(1) 退化为 o(n)。此时便需要进行扩容。
考虑到 Redis 是单线程的,如果一次性做 rehash,将会影响 Redis 的响应速度,因此采用了渐进式 rehash 的fang’shi
具体来说:
- ht[0] 指向哈希桶数组
- 创建一个更大的哈希桶数组 ht[1]
- 维护一个变量 rehashindex
- 每次对 Hash 进行增删改查时,将 rehashindex 所指向的哈希桶中的所有键值对 rehash 到 ht[1] 中
- 重复,直至所有的键值对都已经 rehash 到 ht[1]
- 释放原有的哈希桶数组,让 ht[0] 指向新哈希桶数组
三、List
1. 说明
List ,即列表。
2. 底层实现
- 当存储的数据较少时,使用压缩列表作为底层存储结构
- 当存储的数量较多时,使用双向链表作为底层存储结构
- Redis 之后,新增了 “快速列表” 这一数据结构,它是压缩列表和双向链表的结合,简单来说,多个元素组合成压缩链表,多个压缩列表串联成双向链表。使用 “快速列表” 时,具有双向链表快速插入、删除的优点,又可以借助压缩列表节省空间占用
四、Set
1. 说明
Set,无序集合,要求集合元素唯一。
2. 底层实现
当元素都是整数且元素数量少于 512 时,使用整数数组作为底层存储结构
结构定义如下:
1
2
3
4
5
6
7
8typedf struct inset{
// 指定编码方式,默认为 INSET_ENC_INT16
uint32_t encoding;
// 集合内成员的总个数
uint32_t length;
// 实际存储成员的数组,数值从小到大依次排列
int8_t contents[];
} inset;否则,使用哈希表作为底层存储结构
五、Sorted Set
1. 说明
Sorted Set,又名 Zset,有序集合,要求集合元素唯一,每个元素关联一个 double 类型的用于排序的分数。
2. 底层实现
3. 适用场景
适用于排行榜类型的业务场景,例如音乐排行榜、贡献榜等。
六、特殊类型 - geospatial
1. 说明
geospatial 能够存储经纬度信息,并且能够基于经纬度进行查询、计算。
2. 底层实现
(1) 经纬度
可以将经纬度看作二维坐标系中的某个点,其值是两个数字的结合。
(2) Sorted Set
使用 Sorted Set 作为 geospatial 的底层数据结构。
(3) GeoHash 编码
Redis 采用了业界广泛采用的 GeoHash 编码方法,这个方法的基本原理是 “二分区间,区间编码”。
它的做法是:
二分区间,区间编码
将数值区间两两拆分,每次拆分时,根据分属左、右区间取值为 0、1,持续拆分获得数位编码
经、纬编码逐位组合,合成单一编码
将经度和维度的编码从头开始逐位取值,拼接在一起,组成一个最终的经纬度编码
为了能高效地对经纬度进行比较,Redis 采用了业界广泛使用的 GeoHash 编码方法,这个方法的基本原理就是“二分区间,区间编码”。
当我们要对一组经纬度进行 GeoHash 编码时,我们要先对经度和纬度分别编码,然后再把经纬度各自的编码组合成一个最终编码。
首先,我们来看下经度和纬度的单独编码过程。
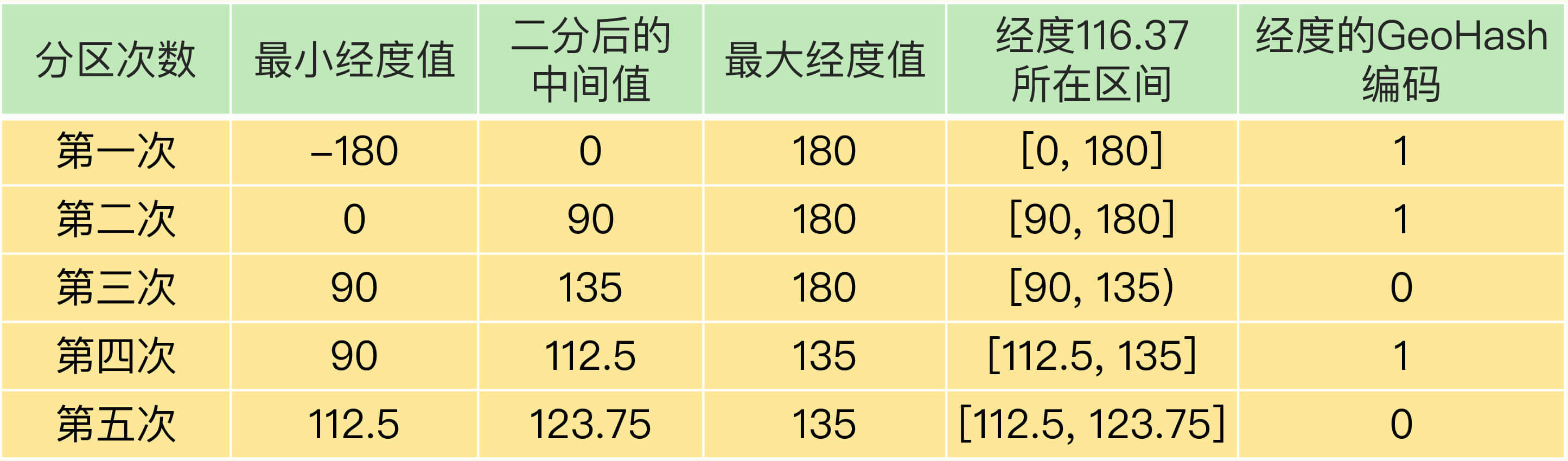
对于一个地理位置信息来说,它的经度范围是[-180,180]。GeoHash 编码会把一个经度值编码成一个 N 位的二进制值,我们来对经度范围[-180,180]做 N 次的二分区操作,其中 N 可以自定义。
在进行第一次二分区时,经度范围[-180,180]会被分成两个子区间:[-180,0) 和[0,180](我称之为左、右分区)。此时,我们可以查看一下要编码的经度值落在了左分区还是右分区。如果是落在左分区,我们就用 0 表示;如果落在右分区,就用 1 表示。这样一来,每做完一次二分区,我们就可以得到 1 位编码值。
然后,我们再对经度值所属的分区再做一次二分区,同时再次查看经度值落在了二分区后的左分区还是右分区,按照刚才的规则再做 1 位编码。当做完 N 次的二分区后,经度值就可以用一个 N bit 的数来表示了。
举个例子,假设我们要编码的经度值是 116.37,我们用 5 位编码值(也就是 N=5,做 5 次分区)。
我们先做第一次二分区操作,把经度区间[-180,180]分成了左分区[-180,0) 和右分区[0,180],此时,经度值 116.37 是属于右分区[0,180],所以,我们用 1 表示第一次二分区后的编码值。
接下来,我们做第二次二分区:把经度值 116.37 所属的[0,180]区间,分成[0,90) 和[90, 180]。此时,经度值 116.37 还是属于右分区[90,180],所以,第二次分区后的编码值仍然为 1。等到第三次对[90,180]进行二分区,经度值 116.37 落在了分区后的左分区[90, 135) 中,所以,第三次分区后的编码值就是 0。
按照这种方法,做完 5 次分区后,我们把经度值 116.37 定位在[112.5, 123.75]这个区间,并且得到了经度值的 5 位编码值,即 11010。这个编码过程如下表所示:
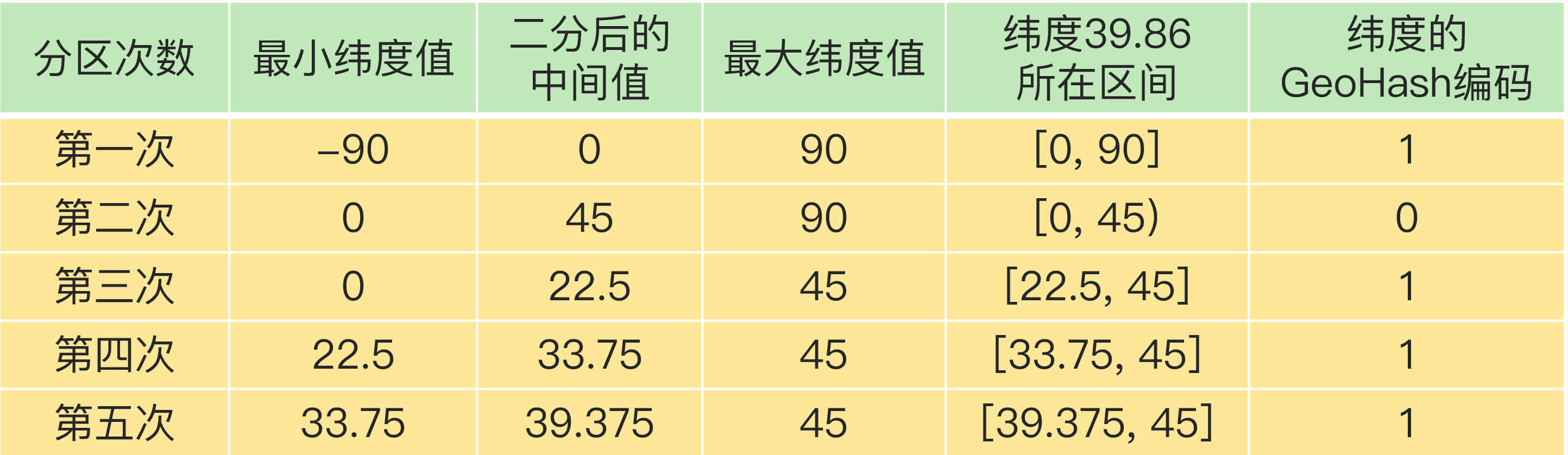
对纬度的编码方式,和对经度的一样,只是纬度的范围是[-90,90],下面这张表显示了对纬度值 39.86 的编码过程。
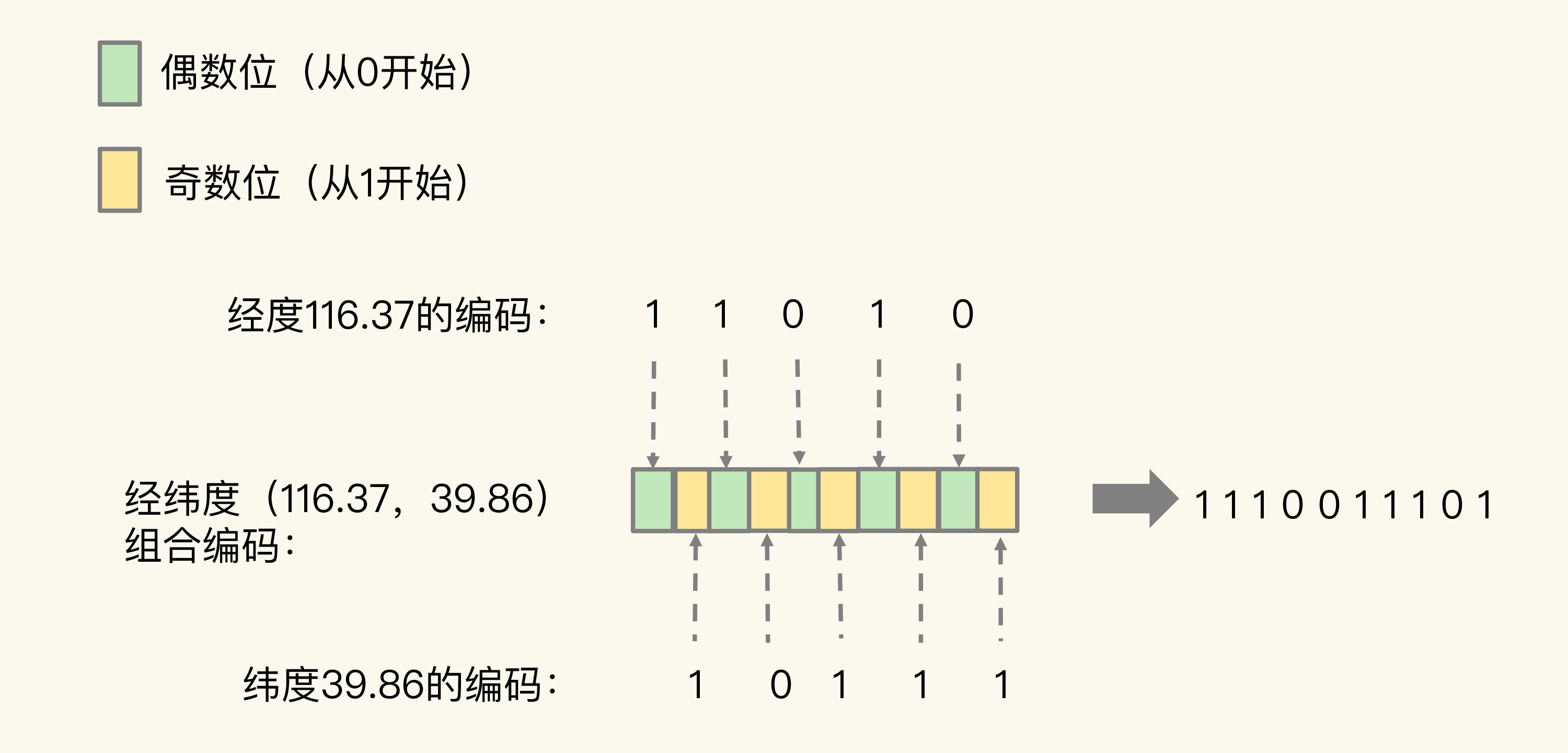
当一组经纬度值都编完码后,我们再把它们的各自编码值组合在一起,组合的规则是:最终编码值的偶数位上依次是经度的编码值,奇数位上依次是纬度的编码值,其中,偶数位从 0 开始,奇数位从 1 开始。
我们刚刚计算的经纬度(116.37,39.86)的各自编码值是 11010 和 10111,组合之后,第 0 位是经度的第 0 位 1,第 1 位是纬度的第 0 位 1,第 2 位是经度的第 1 位 1,第 3 位是纬度的第 1 位 0,以此类推,就能得到最终编码值 1110011101,如下图所示:
用了 GeoHash 编码后,原来无法用一个权重分数表示的一组经纬度(116.37,39.86)就可以用 1110011101 这一个值来表示,就可以保存为 Sorted Set 的权重分数了。
当然,使用 GeoHash 编码后,我们相当于把整个地理空间划分成了一个个方格,每个方格对应了 GeoHash 中的一个分区。
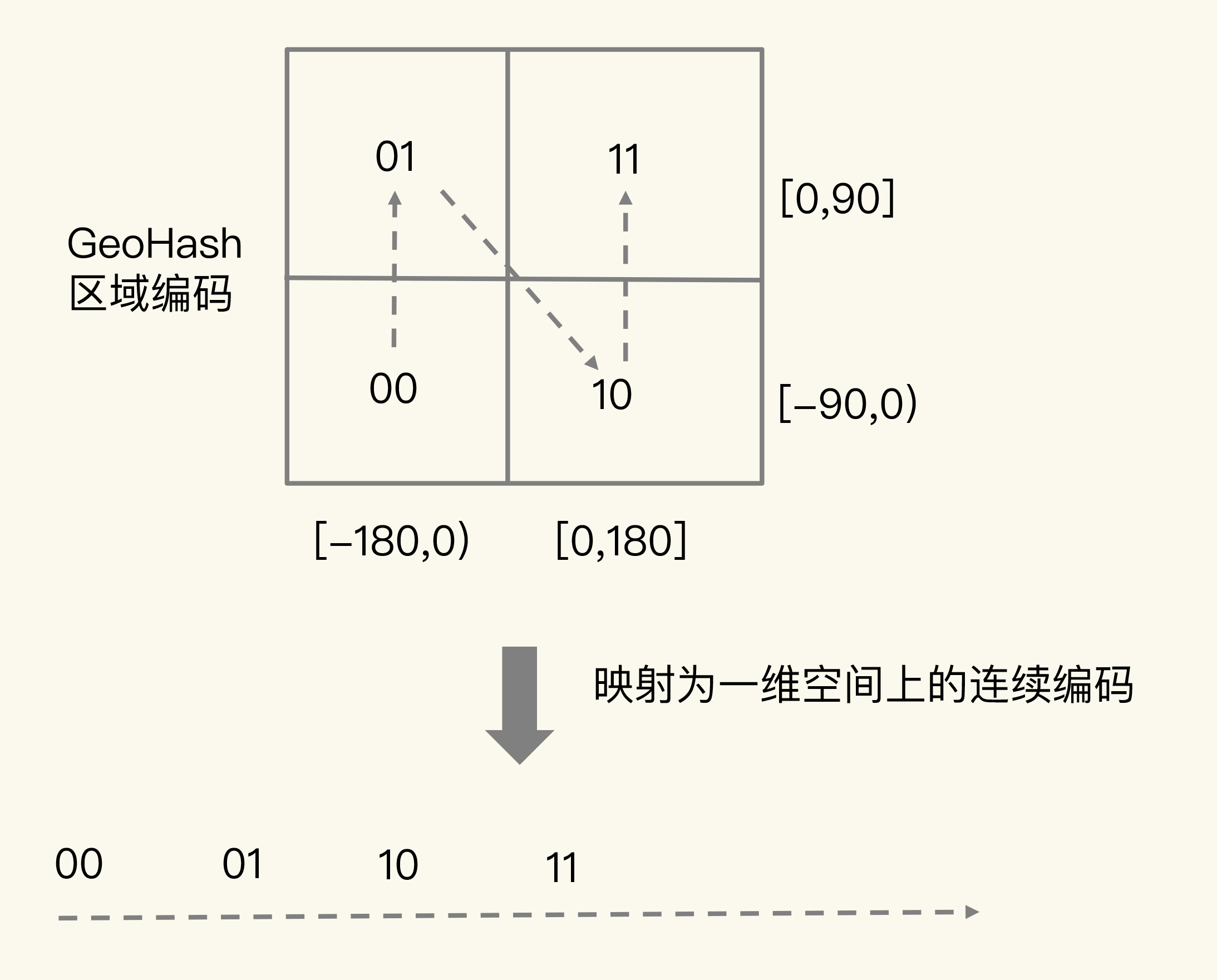
举个例子。我们把经度区间[-180,180]做一次二分区,把纬度区间[-90,90]做一次二分区,就会得到 4 个分区。我们来看下它们的经度和纬度范围以及对应的 GeoHash 组合编码。
- 分区一:[-180,0) 和[-90,0),编码 00;
- 分区二:[-180,0) 和[0,90],编码 01;
- 分区三:[0,180]和[-90,0),编码 10;
- 分区四:[0,180]和[0,90],编码 11。
这 4 个分区对应了 4 个方格,每个方格覆盖了一定范围内的经纬度值,分区越多,每个方格能覆盖到的地理空间就越小,也就越精准。我们把所有方格的编码值映射到一维空间时,相邻方格的 GeoHash 编码值基本也是接近的,如下图所示:
所以,我们使用 Sorted Set 范围查询得到的相近编码值,在实际的地理空间上,也是相邻的方格,这就可以实现 LBS 应用“搜索附近的人或物”的功能了。
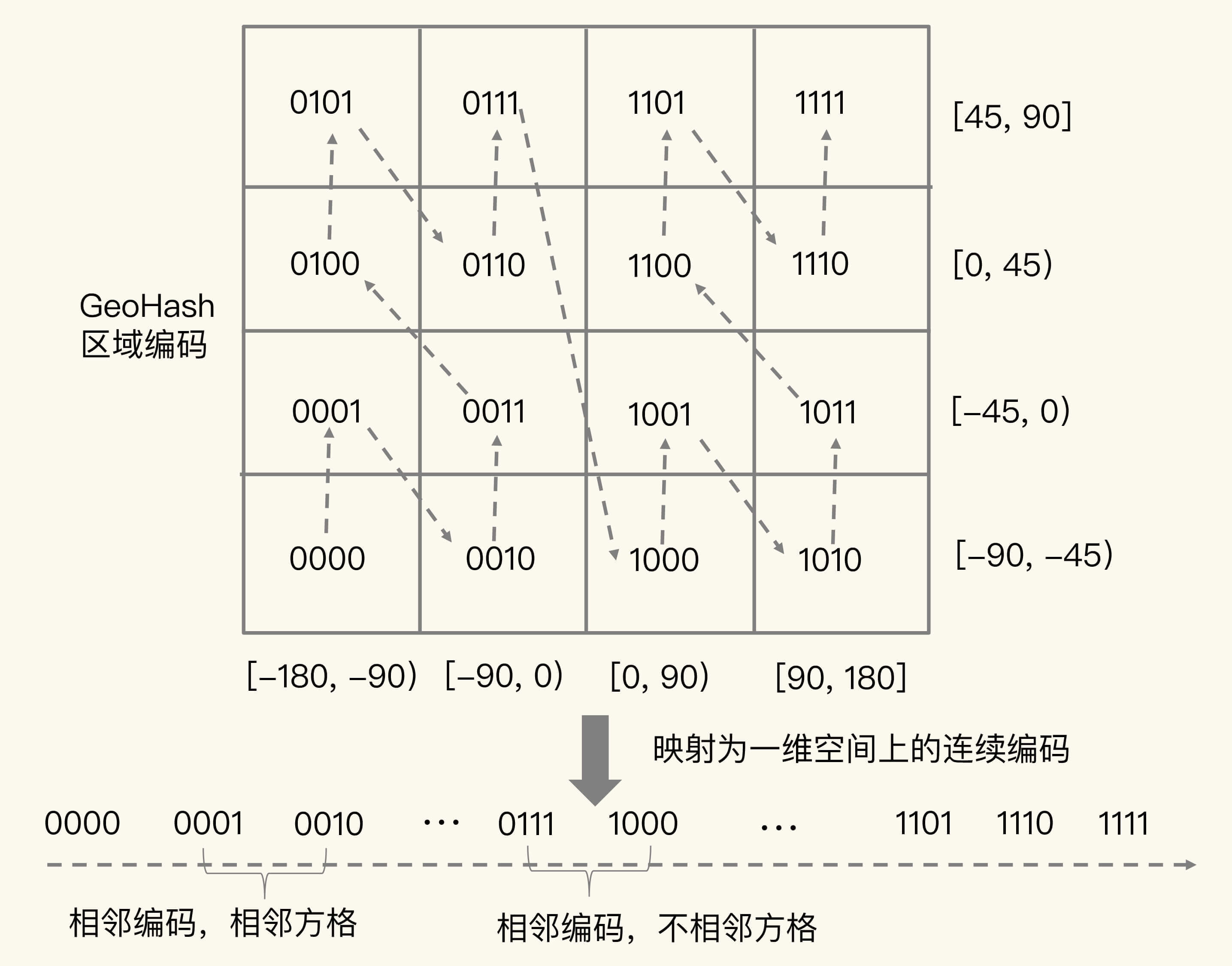
不过,我要提醒你一句,有的编码值虽然在大小上接近,但实际对应的方格却距离比较远。例如,我们用 4 位来做 GeoHash 编码,把经度区间[-180,180]和纬度区间[-90,90]各分成了 4 个分区,一共 16 个分区,对应了 16 个方格。编码值为 0111 和 1000 的两个方格就离得比较远,如下图所示:
所以,为了避免查询不准确问题,我们可以同时查询给定经纬度所在的方格周围的 4 个或 8 个方格。
3. 基本命令
- geoadd:添加地理位置的坐标
- geopos:获取地理位置的坐标
- geodist:计算两个位置之间的距离
- georadius:根据用户给定的经纬度坐标来获取指定范围内的地理位置集合
- georadiusbymember:根据储存在位置集合里面的某个地点获取指定范围内的地理位置集合
- geohash:返回一个或多个位置对象的 geohash 值
七、特殊类型 - hyperloglog
1. 说明
hyperloglog 是一种基数估算算法。
所谓基数,就是一批数据中不重复元素的个数。所谓基数估算,就是估算一批数据的基数。
如果想得到精确的基数,可以通过 Set 的方式,但这种方式最少都得存储所有的 key,虽然准确度高,但是空间复杂度也很高。
如果希望 “相对不准确地” 获取一批数据的基数,可以使用基数估算算法。hyperloglog 就是一种优秀的基数估算算法,具体实现方式这里暂不做展开。
2. 适用场景
访问数、在线用户数、共同好友数等统计费时费力且可以接收一定偏差的计数。
八、特殊类型 - Bitmaps
1. 说明
Bitmaps are not an actual data type, but a set of bit-oriented operations defined on the String type. Since strings are binary safe blobs and their maximum length is 512 MB, they are suitable to set up to 232 different bits.
Bit operations are divided into two groups: constant-time single bit operations, like setting a bit to 1 or 0, or getting its value, and operations on groups of bits, for example counting the number of set bits in a given range of bits (e.g., population counting).
One of the biggest advantages of bitmaps is that they often provide extreme space savings when storing information. For example in a system where different users are represented by incremental user IDs, it is possible to remember a single bit information (for example, knowing whether a user wants to receive a newsletter) of 4 billion of users using just 512 MB of memory.
Bitmaps 并不是真实的数据接口,而是定义在 String 类型上的一个面向字节操作的集合。
Bitmaps 通过设置字符串中每一个 Bit 位来达到存取数据的目的,其最大优势在于存储数据时可以极大地节省空间。
2. 适用场景
适用于存储值二元且键递增的数据。
例如存储 1 万个用户的登录情况,如果只要求存储登录 / 未登录,且用户 id 自增,便可以使用 Bitmaps 存储。
九、Stream
具体请看:
Redis 消息队列 - 三、基于-Stream-的消息队列
参考
- Redis
- Redis 教程 | 菜鸟教程
- Redis数据库学习教程(快速入门版)
- Redis 核心技术与实战