MySQL 索引原理
本文将介绍 MySQL 中索引的原理。
一、如果没有索引
在没有索引的情况下,如果我们希望查找某一条数据,只能通过遍历查找(首先遍历由数据页组成的双向链表,在每个数据页中再遍历由记录组成的单向链表),这是非常耗时的。
因此,我们希望通过索引快速查找到数据。
二、InnoDB 索引方案
1. 底层数据结构
(1) 什么是 B+ 树?
具体请看:
(2) 为什么使用 B+ 树?
与 B 树等数据结构相比,B+ 树具有以下好处:
B+ 树的叶子节点有链表连接,方便遍历
B+ 树的数据都存在在叶子节点中,每次查询的路径长度相同,便于估算查询成本
B+ 树的非叶节点只存储索引记录,其大小必然小于叶子节点中的数据记录,因此 B+ 树的非叶节点的孩子树更多,相应地 B+ 树的层级也能压得更低
与 Hash 相比,B+ 树在范围查询、排序、模糊查询、聚合运算时更有优势
与跳表、红黑树相比,B+ 树查找时所需的 IO 次数更少
2000w 以内的数据,可以通过三层的 B+ 树存储;
而跳表、红黑树的层级将会高得多,这导致磁盘 IO 次数的增加
2. 索引记录
在 InnoDB 中,索引以 “索引记录” 的形式存在,它包含索引值及页编号。
- 索引值:所指向的页的记录中的最小索引值
- 页编号:所指向的页的编号
查找数据时,首先根据索引值找到对应的 “索引记录”,然后就可以根据页编号向下查找,直至定位到数据所在的页。
- 直接:根据页编号找到的页就是数据页
- 间接:根据页编号找到的页是索引数据页,需要在索引数据页中寻找索引记录,继续向下索引
3. 索引数据页
在 InnoDB 中, “索引记录” 会和普通的数据记录一样存储在 数据页 中,需要注意的是:
索引数据页存储索引记录;
数据页存储数据记录
通过这种方式,”索引记录” 和数据记录都可以使用数据页进行存储,为了便于区分,将存储 “索引记录” 的数据页简称为 “索引数据页”
“索引记录” 和数据记录通过 “记录头信息” 中的
record_type属性进行区分“索引记录” 中只有索引值和页编号两列;
数据记录中包含记录中的列及隐藏列
“记录头信息” 中的 min_rec_mask 用于标识 “索引数据页” 中的最小索引记录
4. “索引数据页” 和 “记录数据页” 组成 B+ 树
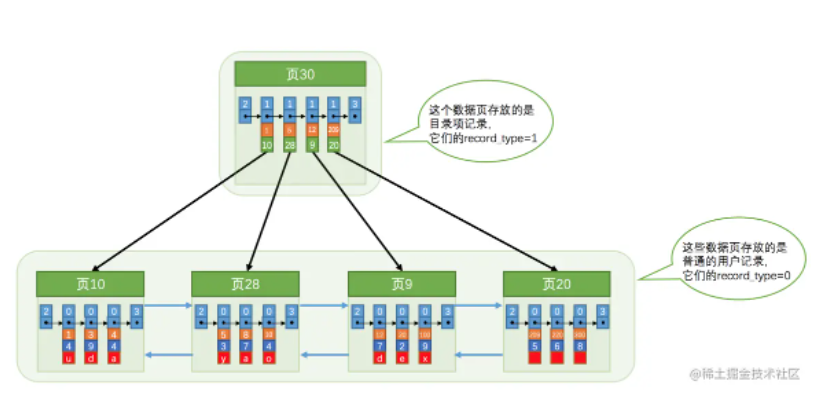
“索引数据页” 和 “记录数据页” 会共同组成一个 B+ 树,其中,非叶节点为 “索引数据页”,叶节点为 “记录数据页”,B+ 树的每一层都会按照索引值排序,非叶节点中的 “索引记录” 会指向下一层的页。
“记录数据页” 中的记录可能是完整的记录,也可能是
索引值 + 主键
5. 页分裂
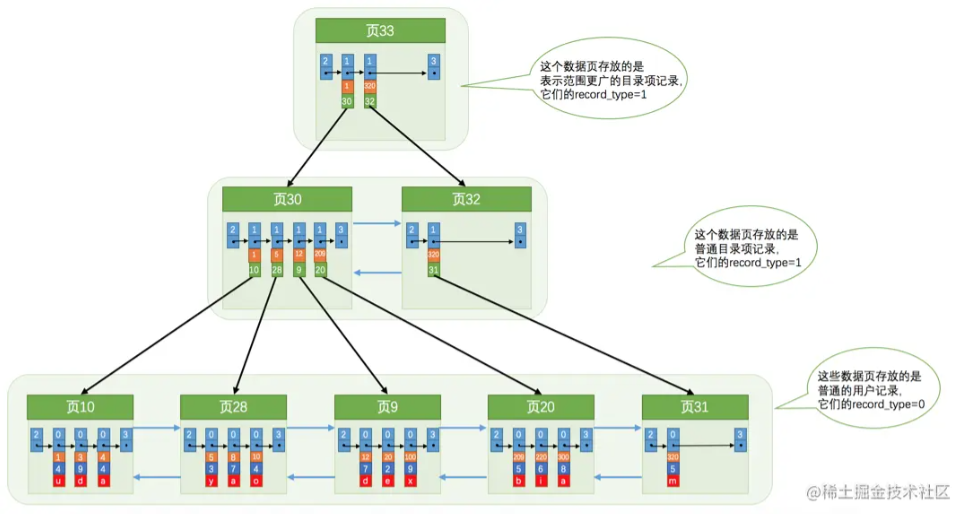
虽然 “索引数据页” 中只存储了包含索引值和页编号的 “索引记录”,单条记录占用的空间较少,记录量相对也较小,但是在 “索引记录” 过多的情况下,也可能超出数据页所允许的最大空间,进而导致无法存放。在这种情况下,索引数据页会进行 “页分裂”,即 B+ 树进行相应的节点插入操作。
6. B+ 树的形成过程
实际上,B+ 树的形成过程是这样的:
每当为一个表创建一个索引时,就为这个索引创建一个 “根节点” 页面
此时根节点就是 “记录数据页”
向表中插入记录时,
- 向聚簇索引插入完整记录
- 向二级索引插入 “不完整” 记录
当根节点可用空间用完时,进行 “页分裂”
此时根节点变为 “索引数据页”,并且逐级上升
7. 聚簇索引
(1) 说明
可以将聚簇索引简单地看作 “主键索引”
如果有主键,则依据主键建索引;
否则,如果有非空的唯一索引,根据其建索引;
否则,隐式定义一个 row_key,根据其建索引
聚簇索引具有以下特点:
B+ 树依据主键排序
非叶子节点存储各个项的是
主键值 + 下一级节点页号叶子节点存储的各个项是 “完整的数据记录”
聚簇索引不需要手动创建,它将会由 InnoDB 自动创建
聚簇索引不仅是索引,并且还是数据的存储方式
也就是说,我们可以通过聚簇索引快速查找数据,并且数据本身也是存储于聚簇索引之中。
(2) 查询流程
- 首先获取索引根节点的页号,访问根节点页
- 通过 B+ 树找到 “记录数据页”
- 在 “记录数据页” 中找到 “完整的数据记录”
8. 二级索引
(1) 说明
- 可以将二级索引简单理解为 “非主键索引”
- 二级索引具有以下特点:
- B+ 树依据非主键列排序
- 非叶子节点存储的各个项是
主键值 + 索引值 + 下一级节点页号 - 叶子节点中存储的各个项是 “不完整的数据记录”,即
索引值 + 记录主键
- 二级索引需要手动创建
(2) 查询流程
首先获取索引根节点的页号,访问根节点页
通过 B+ 树找到 “记录数据页”
在 “记录数据页” 中找到 “不完整的数据记录”
根据记录中的主键值,回表(到聚簇索引中查询完整的记录)
(3) 二级索引 - 联合索引
如果为多个列建立索引,称为 “二级索引 - 联合索引”,它具有以下特点:
B+ 树依据多个列排序
首先按列 1 排序,当列 1 相等时按列 2 排序……
非叶子节点存储各个项的是
主键值 + 各个索引值 + 下一级节点页号叶子节点中存储的各个项是 “不完整的数据记录”,即
各个索引值 + 记录主键
(4) 为什么二级索引存储主键值而不存储行指针?
- 优点:减少了行移动或数据页分裂时的二级索引维护工作
- 缺点:通过二级索引查询数据时,需要进行回表
三、MyISAM 索引方案
MyISAM 索引方案与 InnoDB 索引方案最大的区别在于:
- 不像 InnDB 一样将数据存储为索引,而是将索引与数据分开存储
- 记录单独存储于一个文件中,可以通过行号访问到记录
- 索引另外存储至一个文件中,索引的叶子节点存储的是
主键值 + 行号
四、更好地使用 InnoDB 索引
在明白了 InnDB 索引原理后,我们可以更好地使用 InnoDB 索引。
1. 避免索引失效
这里对 MySQL 避免索引失效 中提到的观点做出解释:
避免联合索引失效:
全值匹配:
B+ 树将会依据多个非主键列排序,MySQL 的查询优化功能又可以将查询条件调整为匹配二叉树的顺序,从而可以 “完美” 地运用索引查找
最左前缀法则:
B+ 树首先根据列 1 排序,当列 1 相同时根据列 2 排序…因此,如果要利用索引查找,有且仅有从索引最左列开始,并且不跳列的查询条件回生效
避免在索引列上进行运算操作:
这是因为按顺序排序的索引值在运算后可能会 “失序”
避免查询索引以外的字段:
如果查询了索引以外的字段,当通过索引查询到记录时,为了查询其它字段,还需要拿到主键到聚簇索引中查询完整数据,导致了两次查询
“前模糊查询” 会导致索引失效:
对于值为字符串的索引,B+ 树会依据 “字典序” 进行排序,当进行 “前模糊查询” 时,无法将查询结果限定在某个区间中,只能遍历查询
2. 正确创建索引
只为用于搜索、排序、分组的列创建索引
为值区别更大的列创建索引
假设有一个 status 字段,其值为 0 或 1,为这个字段创建索引没有意义
索引列占用的空间应该尽可能地小,以减小索引 B+ 树的空间占用
避免重复创建索引
1
2
3
4
5
6
7
8-- 重复
KEY idx_name_birthday_phone_number (name(10), birthday, phone_number),
KEY idx_name (name(10))
-- 重复
c1 INT PRIMARY KEY,
UNIQUE uidx_c1 (c1),
INDEX idx_c1 (c1)
3. 使用递增的主键
InnoDB 会为表自动创建聚簇索引,并将数据存储至其中,聚簇索引将根据主键排序。
因此我们很容易可以想到,
- 当插入的记录的主键值依次增大时,可以在数据页中顺序插入并顺序 “扩展页”
- 当插入的记录的主键值忽大忽小时,为了保持 B+ 树的顺序性,需要重复进行 “页分裂” 和 “记录移位”,这将会带来大量的性能损耗,并且还会影响数据页的空间使用率
因此,建议使用递增的主键。
4. 查询覆盖索引
在使用二级索引查询时,如果二级索引中的内容不足以覆盖查询需求,则需要根据主键值到聚簇索引中二次查询(回表)。
在查询时覆盖索引可以有效减少搜索次数,显著提升查询性能。
5. 正确为字符串创建索引
对于类型为字符串的字段,MySQL 支持截取其中的一部分 “前缀” 作为索引。
1 | |
- 如果没有定义索引长度,会将整个字段作为索引,这种情况下索引占用的空间会更大
- 如果定义了索引长度,会截取一部分 “前缀” 作为索引,这种情况下索引占用的空间会更小,但是无法使用 “索引覆盖”(需要回表才能知道对应字段的完整值)
- 当长度过长,索引占用的空间仍然会很大
- 当长度过短,各个记录在该索引上的区分度可能不够高,从而影响索引加快查询的作用
应该定义好长度,做到既节省空间,又可以加快查询。
参考
- MySQL 技术内幕
- MySQL 实战 45 讲
- MySQL 是怎样运行的:从根儿上理解 MySQL