Spring Cloud 链路追踪
本文将说明微服务领域下的链路追踪技术。
一、链路追踪的作用
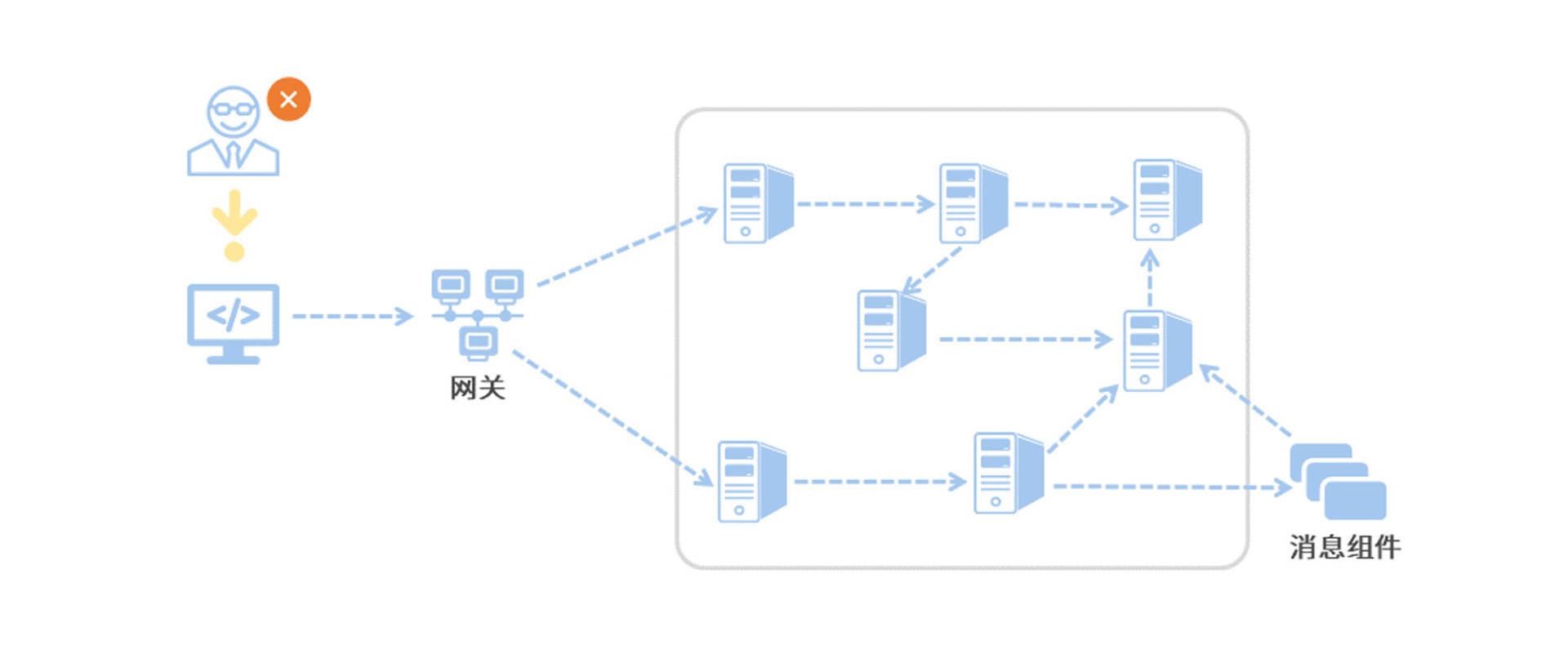
在微服务架构中,各个服务间有复杂的上下游调用关系,同一个请求可能会被分发流转到很多服务中。
假设线上请求报错,我们需要找出各个微服务中的所有相关日志,将其梳理、串联成 “调用链”,最终确定错误点。这将是一件不可能完成的任务。
因此,我们希望有一种机制能够将一次请求的所有相关日志串联起来,这便是链路追踪要做的事情。
二、Sleuth
1. 什么是 Sleuth?
Spring Cloud Sleuth 为 Spring Cloud 提供了一种分布式追踪解决方案。
2. 具体做法
链路追踪有两个任务:
- 标记出一次请求对应的所有日志
- 将这些日志按照先后关系梳理成链
Sleuth 的做法为:
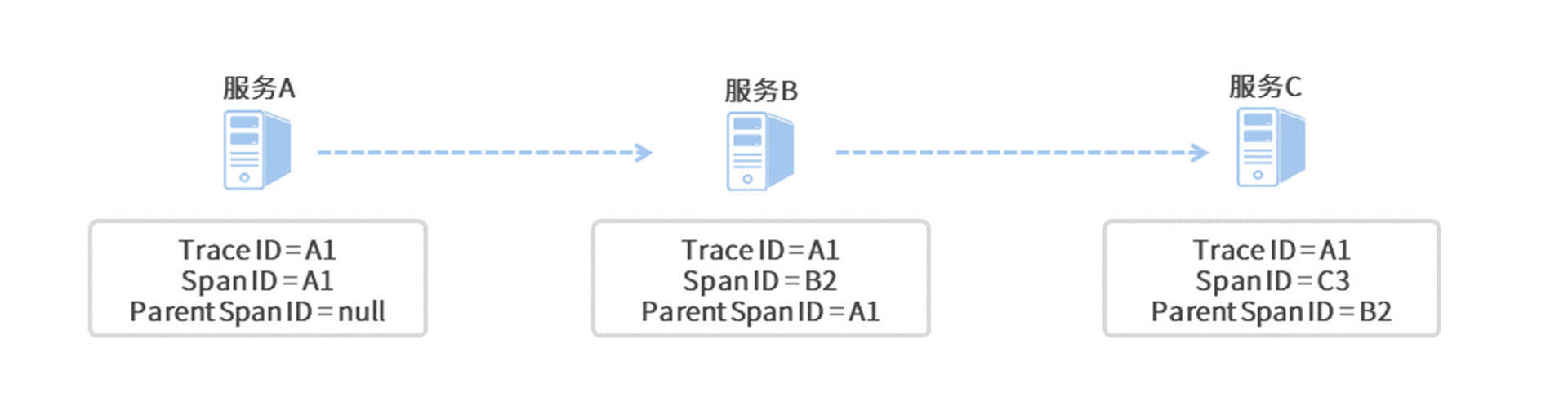
为每次请求生成一个全局唯一的 ID(Trace ID),将它加到所有相关日志中
从而可以根据请求 ID 找到对应的所有日志
将每次服务对请求的处理视为一个 Span(工作单元),生成 Span ID 放置于日志中,并标记开始时间、结束时间
若服务是被上级调用,记录上级的 Span ID
从而可以将日志串联成链
3. 示例 - 日志打标
(1) 引入依赖
1 | |
(2) 配置
1 | |
(3) 打印日志
增加打印日志的操作,如下:
1 | |
(4) 查看日志

可以看到,日志中增加了两个随机 ID,分别是 Trace ID、Span ID。
4. 示例 - 调用链追踪
借助 Zipkin 实现。
Zipkin 可以收集时序化的链路打标数据,并可视化展示调用链。
5. 示例 - 日志检索系统
借助 ELK 组件实现。
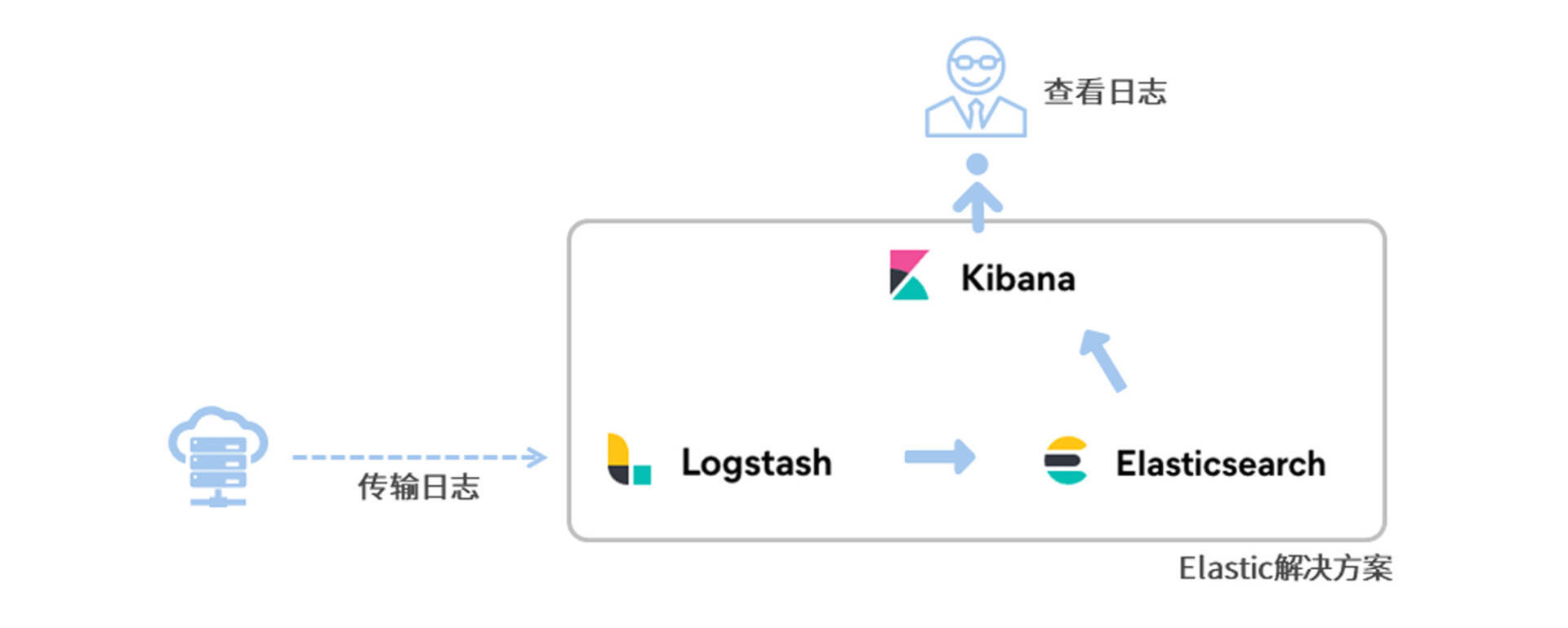
ELK 由 Elasticsearch、Logstash、Kibana 组成,其中:
- Logstash 负责采集日志
- Elasticsearch 负责存储日志、提供数据查询功能
- Kibana 会向 Elasticsearch 查找数据并可视化展示
参考
- Spring Cloud 微服务项目实战