Spring Cloud 服务容错
本文将介绍微服务领域下的服务容错机制。
一、什么是服务雪崩?
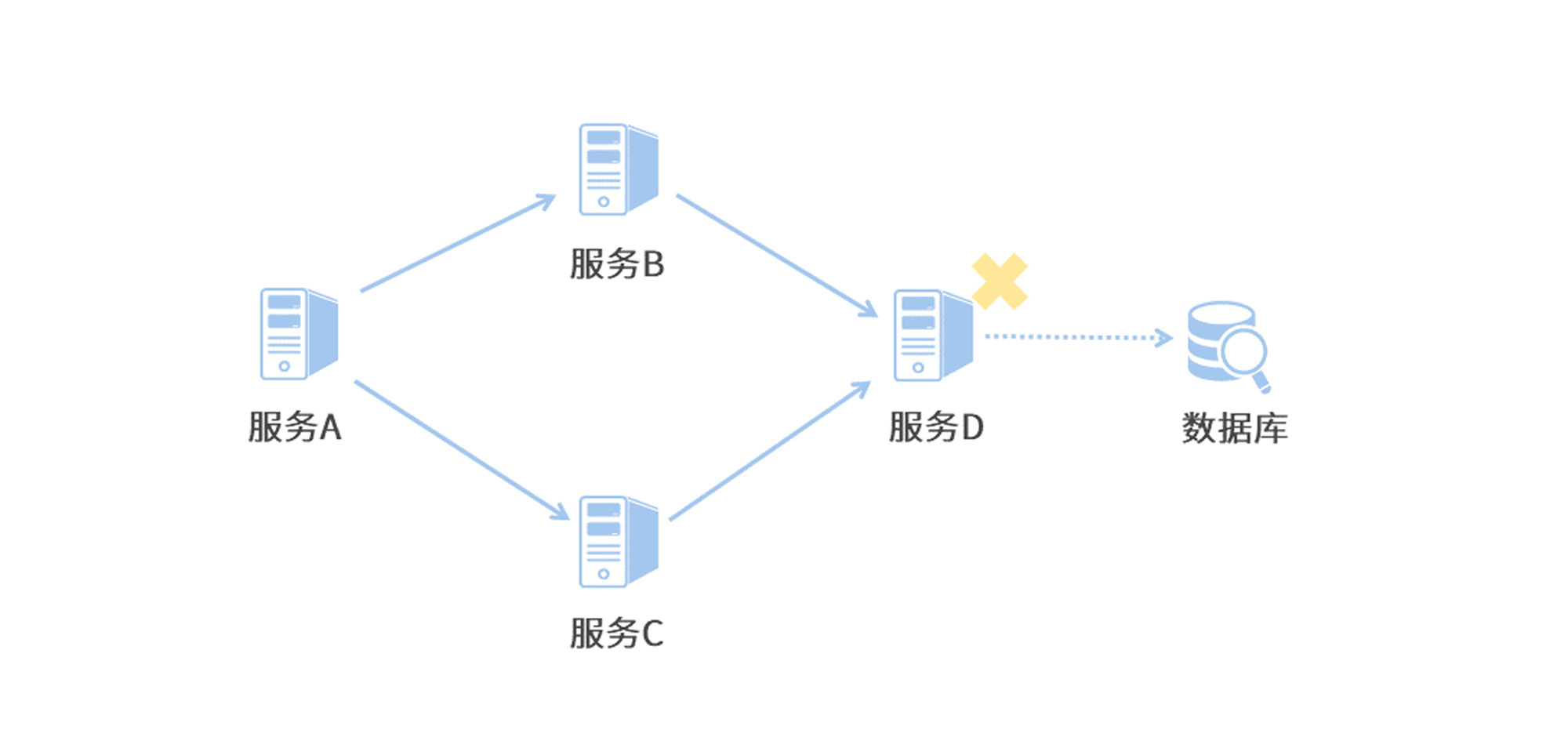
服务无法保证百分百可用,总有出现故障的可能。假如某个服务出现问题,并且服务与服务之间存在依赖,这个问题将会在集群中迅速传播扩大,最终导致整个集群的不可用。这便是服务雪崩。
二、什么是服务容错?
服务容错的核心目的是防止服务雪崩,具体来说:
确保服务发生问题不会拖累其它服务
避免服务发生问题
通过流量控制
三、轻量级服务容错
1. 说明
可以通过 OpenFeign + Hystrix 实现轻量级的客户端的服务容错。
2. 示例
(1) 引入依赖
1 | |
(2) 开启 OpenFeign 对 Hystrix 的支持
1 | |
(3) 实现 fallback 类
编写 fallback 类,该接口需要实现远程方法接口,并在其中书写服务容错逻辑。
1 | |
(4) 配置 fallback 类
配置远程方法接口中的 @FeignClient 注解中的 fallback 属性为 fallback 类。
1 | |
四、Sentinel
1. 什么是 Sentinel?
Sentinel 是面向分布式、多语言异构化服务架构的流量治理组件,主要以流量为切入点,从流量控制、流量路由、熔断降级、系统自适应保护等多个维度来帮助用户保障微服务的稳定性。
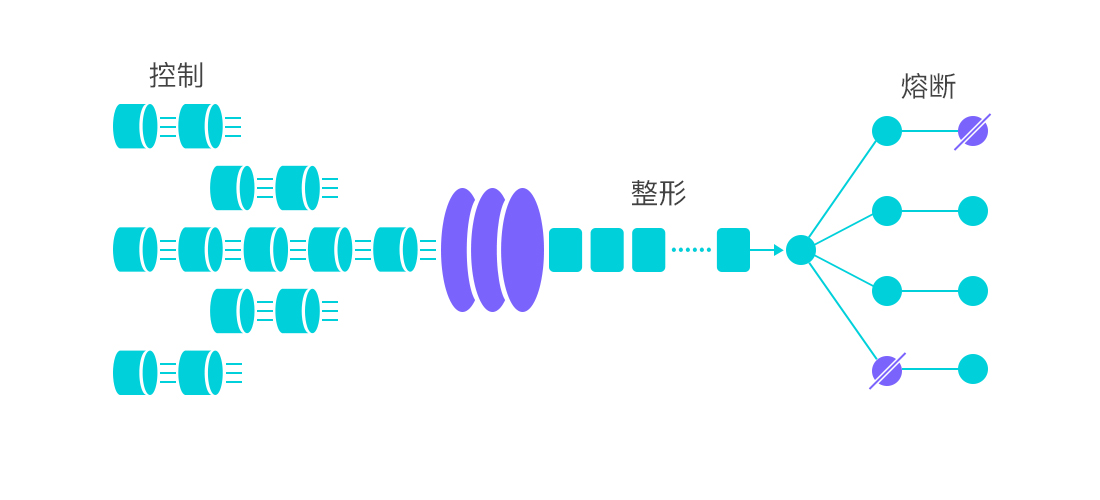
2. 具体做法
(1) 服务雪崩的原因与解决方案
服务雪崩的主要原因有两个:
- 一是外部的高并发流量导致的请求数量增多
- 二是内部服务工作异常
Sentinel 的解决方案是:
针对原因一,通过流量控制避免过多流量涌入
针对原因二,通过降级、熔断处理异常
(2) 流量控制
流量控制的核心是限流,也就是限制访问流量。
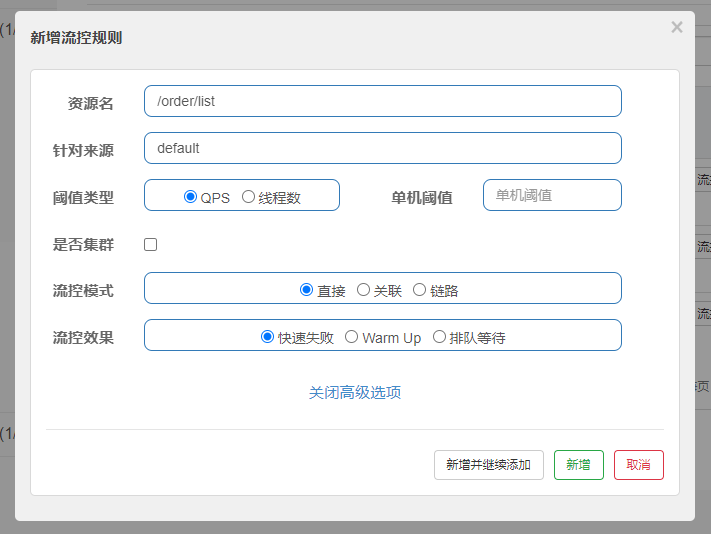
Sentinel 支持从阈值类型、流控模式、流控效果等方面配置流控规则,具体来说:
阈值类型:可以设置为 QPS、线程数
流控模式:
- 直接:当当前资源的访问量达到阈值时,对当前资源进行流控
- 关联:当关联资源的访问量达到阈值时,对当前资源进行流控
- 链路:当指定链路上的访问量达到阈值时,对当前资源进行流控
流控效果:
快速失败:将请求直接拒绝
Warm Up:在规定的预热时间内,从低到高逐渐拉升流量阈值
同一套代码同一个平台,”刚启动时” 和 “运行一段时间数据已经缓存于内存时” 可以承载的访问量差距可能非常大,可以通过预热的方式逐步放量,避免系统在缓存未充分构建时被大量流量压垮
排队等待:将请求放入队列中,排队等待被处理
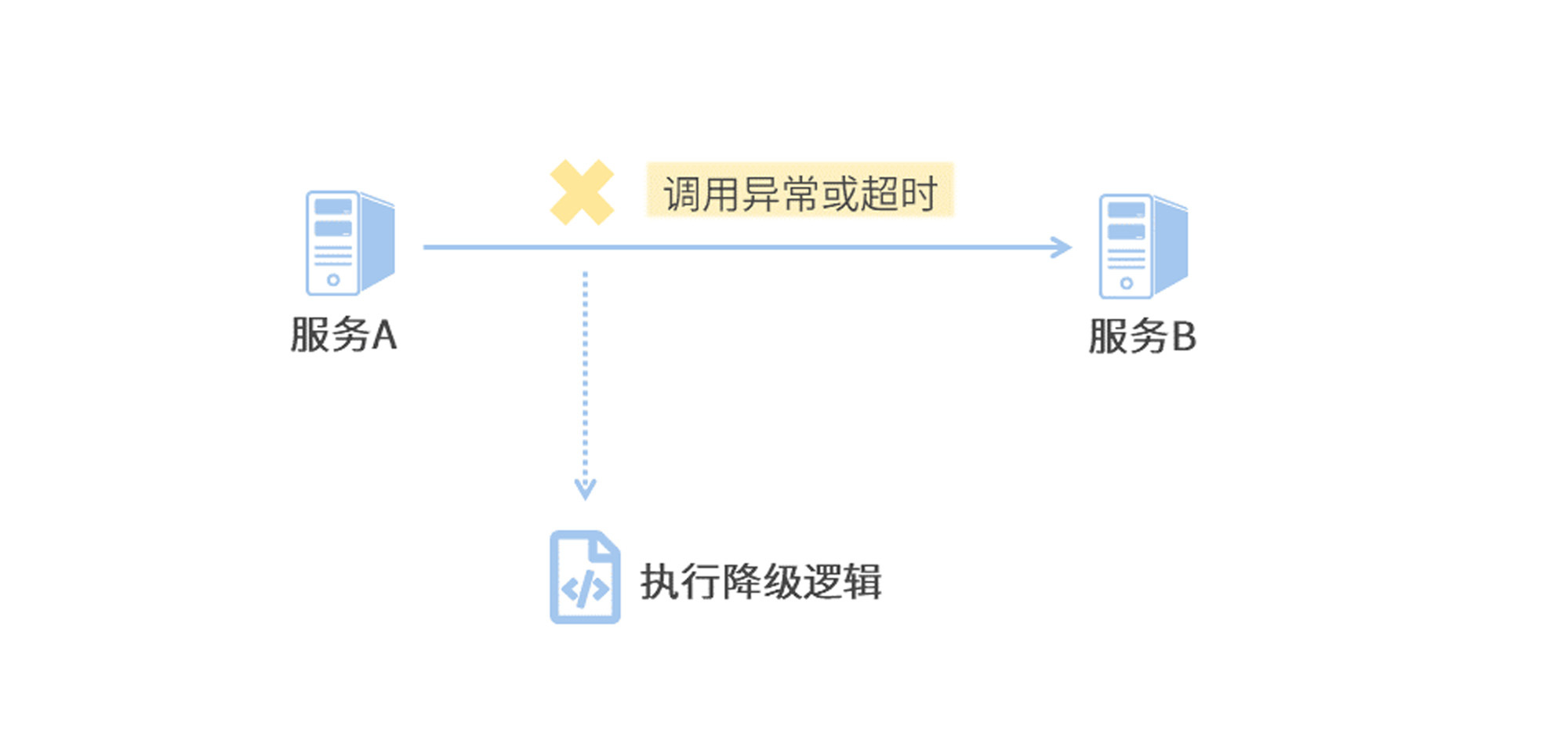
(3) 降级
在检测到请求超时、执行异常时,执行降级逻辑。
所谓降级逻辑就是兜底方案,可以选择静默处理(忽略异常继续向下执行)、尝试重新发起请求、尝试恢复异常服务等。
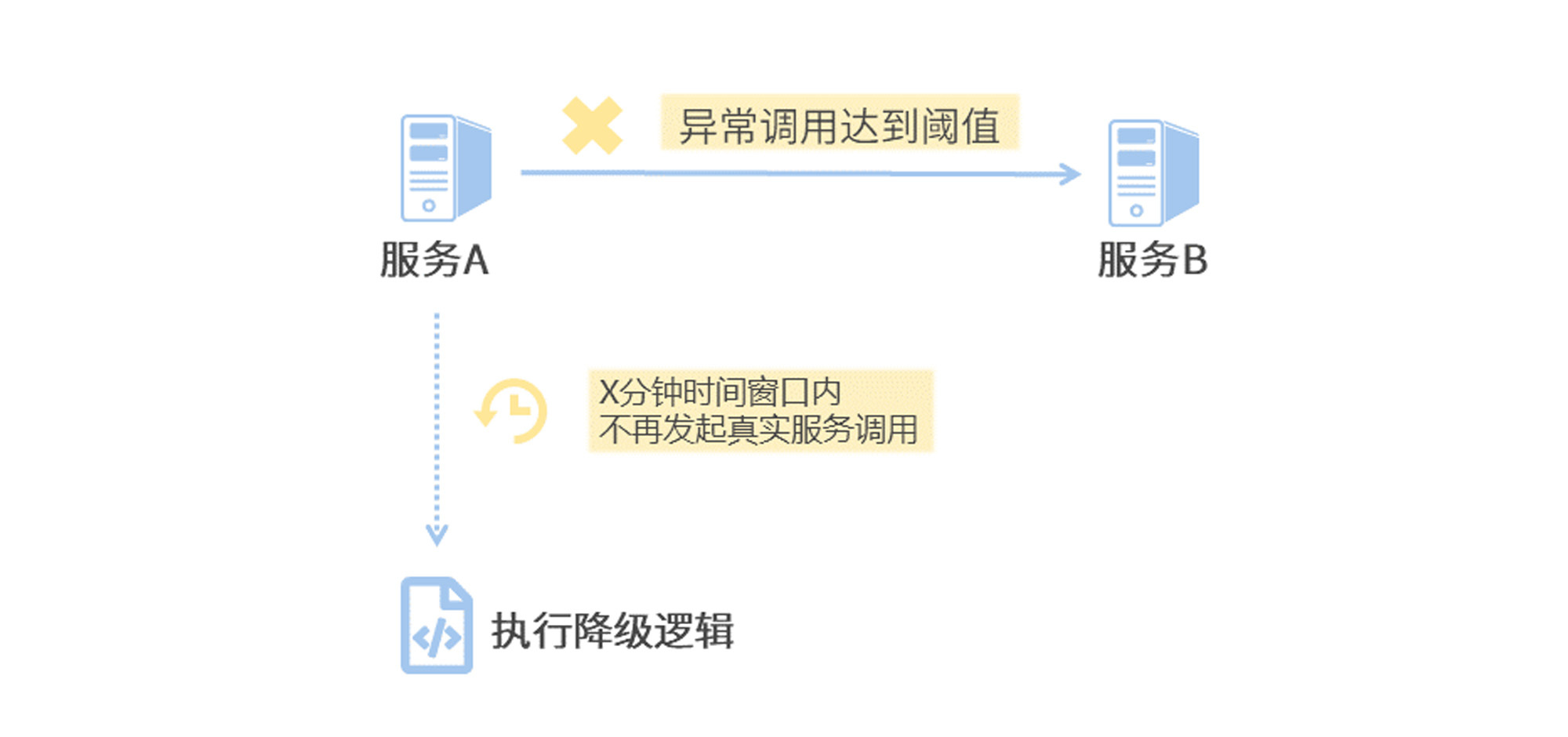
(4) 熔断
当检测到大量的异常调用时,暂时停止对服务的真实调用,直接执行降级逻辑。
Sentinel 支持配置慢调用比例、异常比例、异常数等指标作为阈值,判断是否进行熔断。
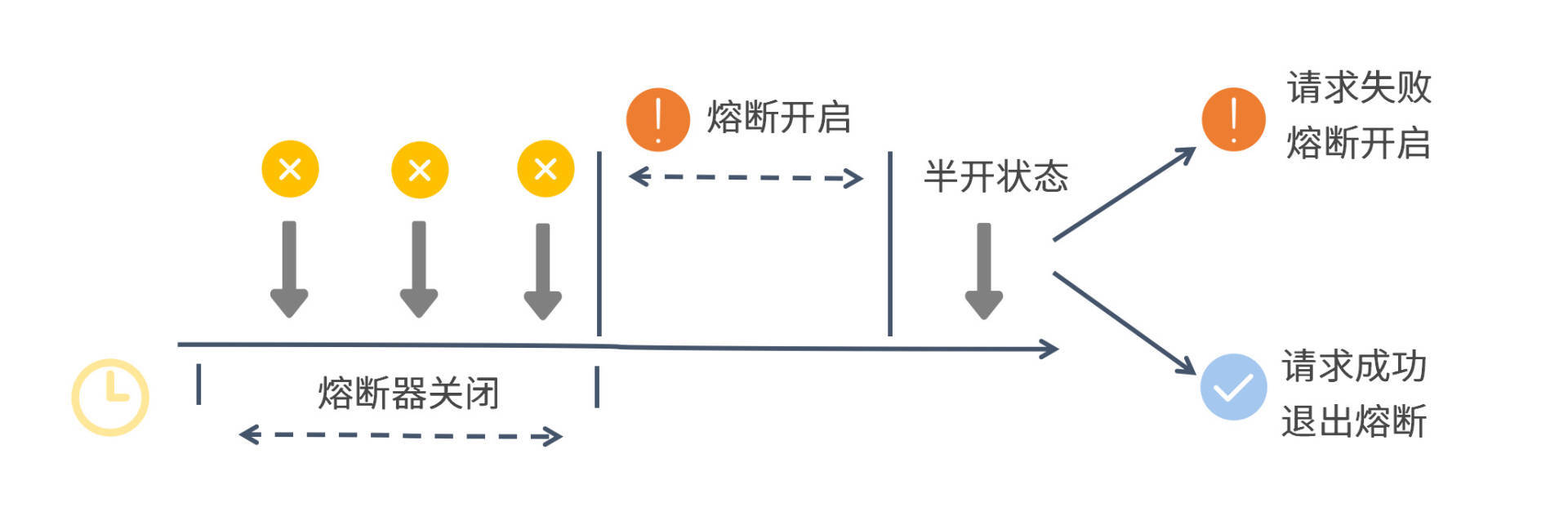
Sentinel 的熔断器会在开启、半开、关闭三个状态之间切换,具体来说:
- 当判断应该熔断时,开启熔断器
- 当熔断时间结束后,熔断器状态变为半开。在半开状态下,如果有新请求,Sentinel 会让请求执行,若执行成功,熔断器状态变为关闭,若执行失败,则熔断器将继续开启一个熔断时间
3. 示例
(1) 引入依赖
1 | |
(2) 配置
1 | |
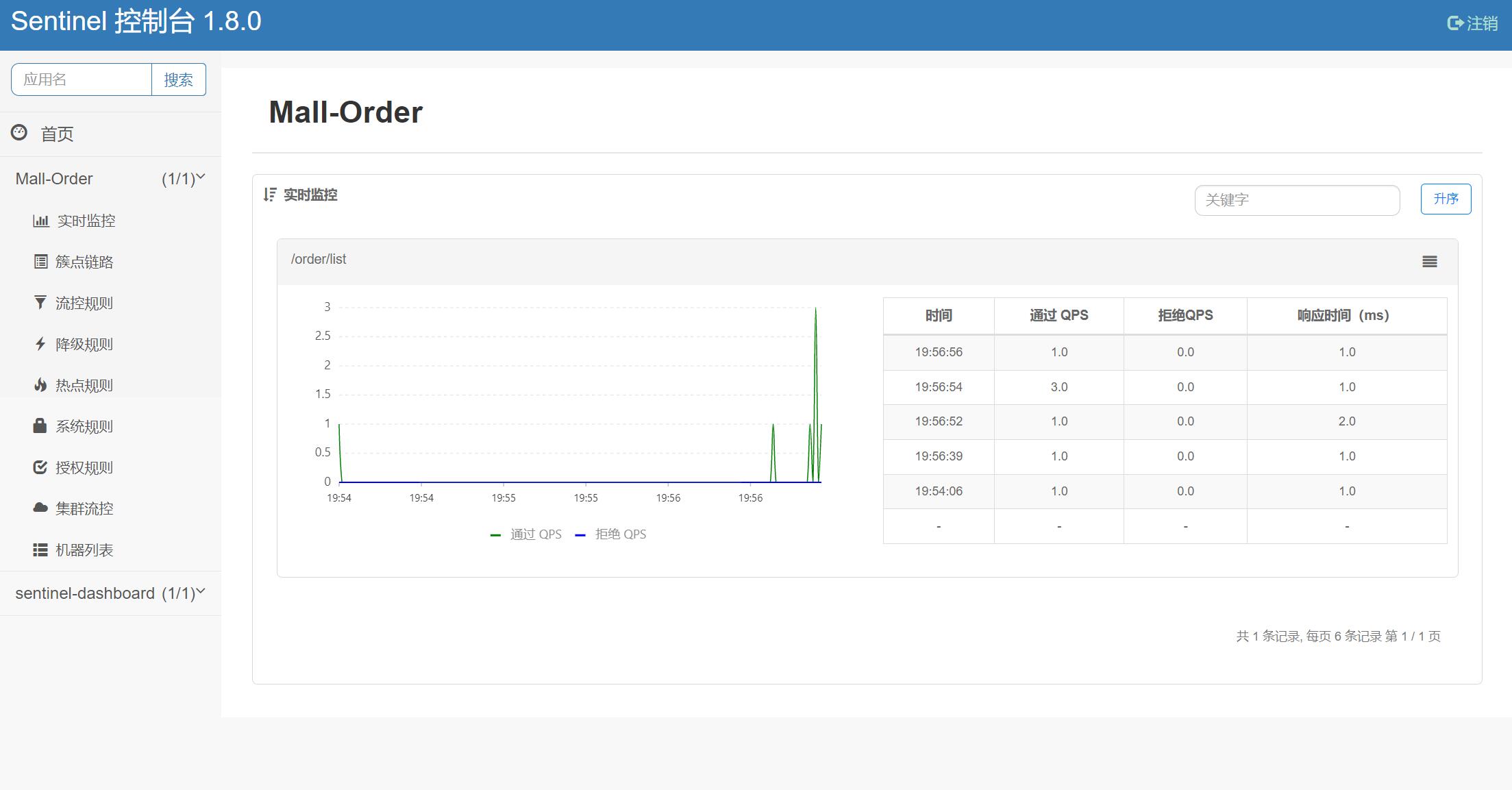
(3) 在 Sentinel 中查看
启动服务后,对该服务中的接口发出请求,触发服务信息的上报,若干秒后便可以在 Sentinel 控制台中查看到该服务信息。
(4) 流量控制
在 Sentinel 控制台中配置流控规则。
(5) 降级
使用 @SentinelResource 注解接口,其中:
- blockHandler 属性应填入方法名,该方法用于处理被流控的请求
- fallback 属性应填入方法名,该方法用于处理处理过程中发生异常的请求
1 | |
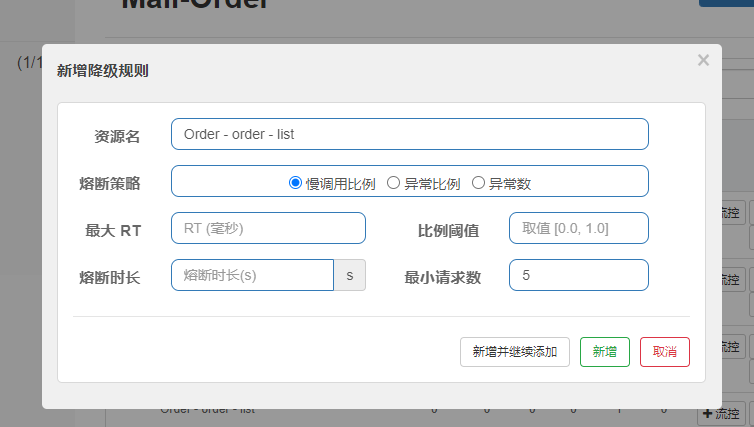
(6) 熔断
在 Sentinel 控制台中配置熔断规则(降级规则)。
参考
- Spring Cloud 微服务项目实战