SQL 关系数据结构
本文将详细介绍关系数据结构。
一、关系
关系模型的数据结构非常简单,只包含单一的数据结构——关系。在用户看来,关系模型中数据的逻辑结构是一张扁平的二维表。关系模型的数据结构虽然简单却能够表达丰富的语义,描述出现实世界的实体以及实体间的各种联系。
关系模型建立在几何代数的基础上,这里从集合论角度给出关系数据结构的形式化定义。
1.域
域是一组具有相同数据类型的值的集合,是属性取值范围的集合。
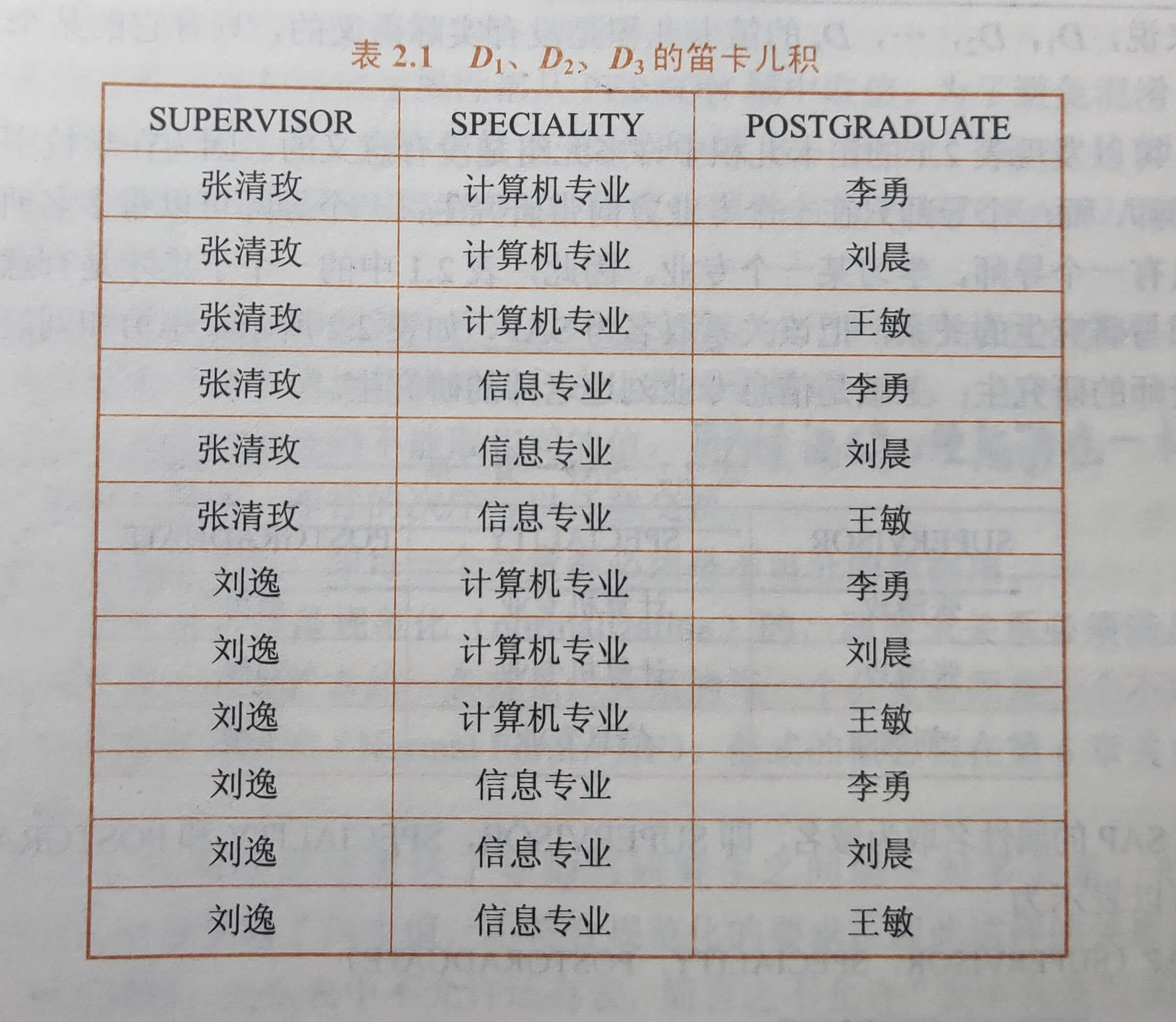
2.笛卡儿积
笛卡儿积为多个域相乘。
1 | |
笛卡儿积可表示为一张二维表,表中每行对应一个元组,表中每列对应一个属性。
给出三个域:
D1=SUPERVISOR = { 张清玫,刘逸 }
D2=SPECIALITY= {计算机专业,信息专业}
D3=POSTGRADUATE = {李勇,刘晨,王敏}
则D1,D2,D3的笛卡儿积为:
D=D1×D2×D3 ={
(张清玫, 计算机专业, 李勇),
(张清玫, 计算机专业, 刘晨),
(张清玫, 计算机专业, 王敏),
(张清玫, 信息专业, 李勇),
(张清玫, 信息专业, 刘晨),
(张清玫, 信息专业, 王敏),
(刘逸, 计算机专业, 李勇),
(刘逸, 计算机专业, 刘晨),
(刘逸, 计算机专业, 王敏),
(刘逸, 信息专业, 李勇),
(刘逸, 信息专业, 刘晨),
(刘逸, 信息专业, 王敏)}
共有 12 个元组,每个元组中又有 3 个分量。
3.关系
关系通俗来讲就是表,关系是笛卡儿积的子集。
因为关系一定属于笛卡儿积,而不一定每一条笛卡儿积都有意义。
前面的表中,假设每个学生只有一个老师,则仅有 1/3 的笛卡儿积有意义。
表的每行对应一个元组,每列对应一个属性。
4.属性
- 每一个属性(每一列)都有一个对应名称,即属性名。
- 每一个属性都有对应的取值范围,即域。
- 属性必须是原子的,即不可分割的。
- null 是每一个域的成员,即每个属性都可以取为 null 。空值给数据库的访问和更新带来许多困难,因此应该尽量避免使用空值。
5.码
如果某一个元素组能够唯一地标识一个元组,则称该属性组为超码
如果关系中的某一个元素组为超码(能够唯一地标识一个元组),且最小(元素组的子集无法唯一标识元组),则称该属性组为候选码
如果一个关系有多个候选码,选定其中一个设为主码 ,一般加上下划线表示
候选码的诸多属性称为主属性
6.关系的三种类型
- 基本关系,又称基本表,实际存在的表,是实际存储数据的逻辑表示
- 查询表,是查询结果对应的表
- 视图表,由基本表或其它视图表导出的表,是虚表,不对应任何实际存储的数据
7.关系的性质
- 关系必须是有限集合
- 一个关系中不能有重复的元组,由候选码唯一标识
- 列(属性)的顺序无所谓
- 行(元组)的顺序无所谓
- 同一列一定来自同一个域,不同列可以来自同一个域
- 属性必须是原子的、不可分的
二、关系模式
在关系数据库中,关系模式是“型”,关系是“值”。其关系可以通过下表理解:
| 值 | 型 |
|---|---|
| 变量 | 变量类型 |
| 关系 | 关系模型 |
关系模式就是对关系的描述,关系模式必须指出关系的元组结构,划定完整性约束条件。
关系模式是静态的、稳定的,而关系是动态的、变化的、因关系操作而不断更新的。
三、关系数据库
1.什么是关系数据库
在一个给定的应用领域中,所有关系的集合构成一个关系数据库。
2.关系数据库的型和值
关系数据库的型称为关系数据库模式,是对关系数据库的描述。
关系数据库的值是这些关系模式在某一时刻对应的关系的集合。
四、关系模型的存储结构
由关系数据库管理系统接管,不同系统的存储方式各不相同。
参考
- 数据库系统概论